![[RSS]](./theme/image/rss.png)
Werkstattbericht: Kohlendioxid auf dem Balkon
Im November hatte ich mich gefragt, was wohl die recht deutlichen Spitzen der CO₂-Konzentration auf meinem Balkon verursachen mag, die sich da immer mal wieder zeigen. Um Antworten zu finden, habe ich seit Ende Dezember eine längere Messreihe laufen lassen und derweil vierstündlich Windrichtungen von der Open Weathermap aufgenommen. Das, so hoffte ich, sollte zeigen, woher der Wind weht, wenn die Konzentration auffällige Spitzen hat.
Leider gibt ein schlichter optischer Vergleich von Konzentration (oben) und Windrichtung (unten; hier als Cosinus, damit das Umschlagen von 0 auf 360 Grad nicht so hässlich aussieht) nicht viel her:
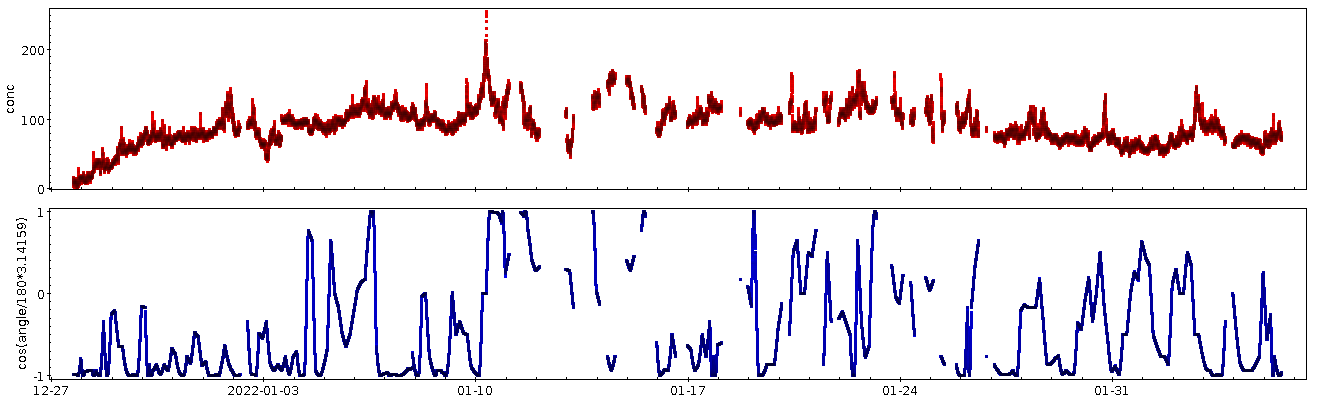
CO₂-Konzentration auf meinem Balkon und Windrichtung für Heidelberg aus der Open Weathermap zwischen Ende Dezember 2021 und Anfang Februar 2022. Die Lücken ergeben sich aus fehlenden Daten zur Windrichtung.
Tatsächlich hilft es ein wenig, wenn mensch das anders plottet. Unten bespreche ich kurz das Programm, das Wind- und CO₂-Daten zusammenbringt. Dieses Programm produziert auch folgenden Plot in Polarkoordinaten:
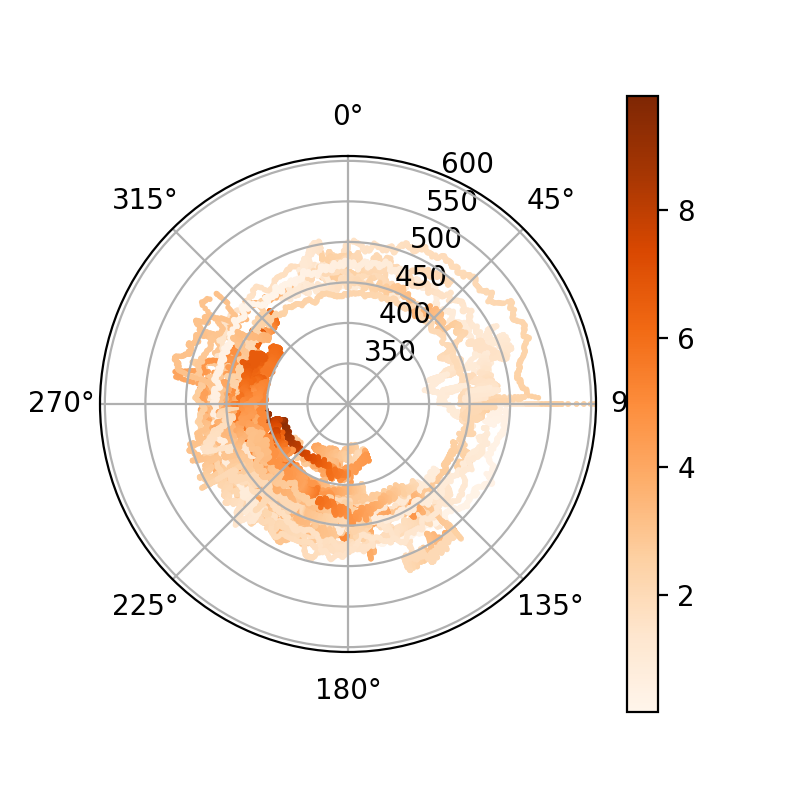
CO₂-Konzentration auf meinem Balkon gegen meteorologische Windrichtung (also: Herkunft des Windes, hier gezählt ab Nord über Ost, so dass das orientiert ist wie eine Landkarte) und farbkodierte Windgeschwindigkeit (in Meter pro Sekunde). Das ist ein PNG und kein SVG, weil da doch viele Punkte drauf sind und Browser mit so großen SVGs immer noch ins Schlingern kommen.
Ich hatte mich seit einem Monat auf diesen Plot gefreut, weil ich erwartet habe, darin eine ordentliche „Beule“ zu sehen dort, wo die CO₂-Emission herkommt. Gemessen daran ist wirkliche Ergebnis eher ernüchternd. Dort, wo ich die Abgasfahne des Großkraftwerk Mannheim sehen würde, etwas unterhalb der 270°-Linie, ist allenfalls ein kleines Signälchen und jedenfalls nichts, was ich wirklich ernst nehmen würde.
Etwas deutlicher zeichnet sich etwas zwischen 280 und 305 Grad ab, also Westnordwest. Das könnte die Ladenburger Chemieindustrie oder die BASF in Ludwigshafen sein; zu letzterer haben die kritischen Aktionäre im letzten Jahr angesagt, sie emittiere als Konzern 20 Megatonnen Kohlendioxid im Jahr. Wenn, was nicht unplausibel ist, die Hälfte davon am Standort Ludwigshafen anfällt, würden sich diese 10 Mt ganz gut vergleichen mit den 8 Mt, die ich neulich fürs Großkraftwerk gefunden hatte – die Abschätzung von dort, so eine Abgasfahne könne durchaus die Konzentrationsspitzen erklären, kommt also auch für die BASF hin. Allerdings wird deren Emission angesichts des riesigen Werksgeländes natürlich auch verteilter sein…
Also: Überzeugend ist das alles nicht. Ein anderes Feature ist jedoch schlagend, wegen weniger Übermalung – die bei beiden Plots ein echtes Problem ist; nächstes Mal muss ich mit halbtransparenten Punkten arbeiten – noch mehr, wenn ich den Polarplot „ausrolle“, also den Winkel von unten nach oben laufen lasse:
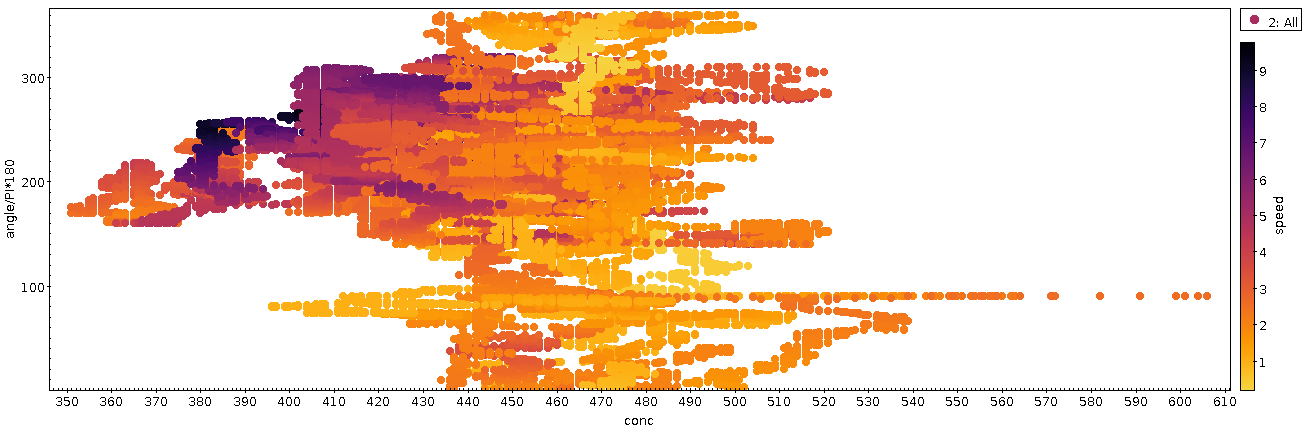
In dieser Darstellung fällt ins Auge, dass die CO₂-Konzentration bei starken (dunkle Töne) Südwest- (um die 225°) -strömungen recht drastisch fällt. Das passt sehr gut zu meinen Erwartungen: Südwestwind schafft hier in der Rheinebene Luft durch die Burgundische Pforte, hinter der im Mittelmeerraum auch jetzt im Winter eifrig Photosynthese stattfindet. Wer drauf aufpasst, sieht die Entsprechungen auch im Polarplot von oben, in dem dann sogar auffällt, dass reiner Südwind gelegentlich noch besser photosynthetisierte Luft heranführt, auch wenn der Wind nicht ganz so stark bläst.
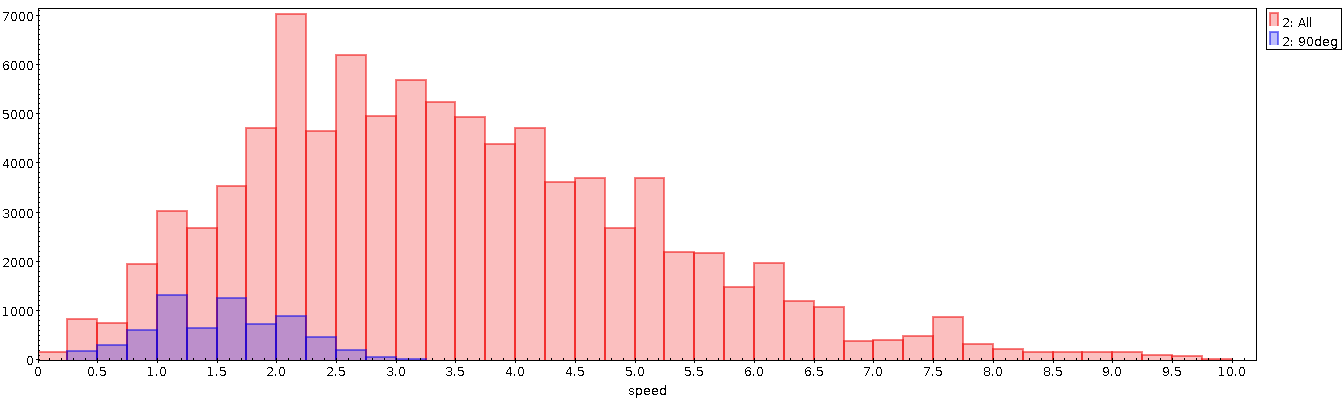
Demgegenüber ist mir eigentlich alles, was sich im nordöstlichen Quadranten des Polarplots (und hier zwischen 0 und 90 Grad) abspielt, eher rätselhaft. Der doppelseitige Sporn bei genau 90 Grad ist vermutlich auf Datenmüll der Wetterstation zurückzuführen: Wahrscheinlich hat die einen Bias, der bei wenig Wind diese 90 Grad ausspuckt. Selbst nach meiner Interpolation (vgl. unten) ist das noch zu ahnen, wenn mensch die Verteilung der Geschwindigkeiten insgesamt (in rot) und die der Geschwindigkeiten rund um einen auffälligen Hügel rund um 90° Windrichtung herum (in blau) ansieht:
Die elegante Schleife, die von (0, 500) über (70, 540) nach (90, 510) führt und die im Polarplot ganz alleine außen vor sich hinläuft, dürfte ziemlich sicher teils physikalisch sein. Dass das da so einen Ring macht, dürfte zwar ein Artefakt meiner gewagten Interpolation sein (vgl. Technics). Der Anstieg als solcher und wohl auch die grobe Verortung dürften aber ganz gut hinkommen. Sieht mensch sich das im zeitlichen Verlauf an, entspricht die Schleife der höchsten Spitze in der ganzen Zeitreihe.
Nur leider ist im Nordosten von meinem Balkon nicht mehr viel: Ein paar Dutzend Häuser und dann der Odenwald, also für fast 10 km nur Bäume. Na gut, und ein Ausflugsrestaurant.
Die aus meiner Sicht plausibelste Interpretation für diese Stelle basiert auf der Beobachtung, dass in der fraglichen Zeit (am 10.1.) wenig Wind wehte, die Temperaturen aber ziemlich niedrig lagen. Vielleicht schauen wir hier wirklich auf die Heizungen der Umgebung? Der Schlot unserer lokalen Gemeinschafts-Gasheizung ist in der Tat so in etwa im Nordosten des Balkons – und vielleicht wurde ja sonst nicht so viel geheizt?
Technics
Die wesentliche Schwierigkeit in diesem Fall war, dass ich viel engmaschiger CO₂-Konzentrationen (alle paar Minuten) habe als Windrichtungen (bestenfalls alle vier Stunden), und zudem viele Windrichtungen aus welchen Gründen auch immer (offensichtlich wäre etwa: zu wenig Wind) fehlen. Auf der positiven Seite erzeugt mein Open Weathermap-Harvester weathercheck.py eine SQLite-Datenbank, so dass ich, wenn es nicht furchtbar schnell gehen muss, recht bequem interessante Anfragen laufen lassen kann.
Mein Grundgedanke war, die beiden einem CO₂-Wert nächsten Wind-Werte zu bekommen und dann linear zu interpolieren[1]. Das ist schon deshalb attraktiv, weil die Zeit (als Sekunden seit 1.1.1970) als Primärschlüssel der Tablle deklariert ist und deshalb ohnehin ein Index darauf liegt.
Dabei sind aber je nach Datenverfügbarkeit ein Haufen Fälle zu unterscheiden, was zu hässlichen if-else-Ketten führt:
def get_for_time(self, time, col_name, default=None):
res = list(self.conn.execute(f"SELECT timestamp, {col_name} FROM climate"
" WHERE TIMESTAMP BETWEEN ? AND ?"
" ORDER BY ABS(timestamp-?) LIMIT 2",
(time-40000, time+40000, time)))
if len(res)!=2:
if default is not None:
return default
raise ValueError(f"No data points close to {time}")
elif abs(res[0][0]-time)<200 and res[0][1] is not None:
return res[0][1]
elif res[0][1] is None or res[1][1] is None:
if default is not None:
return default
raise ValueError("One or more limits missing. Cannot interpolate.")
else:
t1, v1 = res[0]
t2, v2 = res[1]
return (v1*(t2-time)+v2*(time-t1))/(t2-t1)
Die Fallunterscheidung ist:
- Es gibt überhaupt keine Daten innerhalb von einem halben Tag. Dann kann ich nur einen Fehler werfen; zumindest in unseren Breiten sind Windrichtungen eigentlich schon über kürzere Zeiträume hinweg nur lose korreliert.
- Innerhalb von 200 Sekunden der gesuchten Zeit gibt es einen tatsächlichen Messwert, und dieser ist nicht NULL. Dann gebe ich den direkt zurück.
- Einer der beiden Werte, die um die gesuchte Zeit herum liegen, fehlt (also ist NULL). Dann kann ich nicht interpolieren und muss wieder einen Fehler werfen. Hier wäre es nicht viel unplausibler als die Interpolation, wenn ich einfach einen nicht-NULL-Wert nehmen würde; aber es wäre doch nochmal ein Stückchen spekulativer.
- Ansonsten mache ich einfach eine lineare Interpolation.
NULL-Werte machen die Dinge immer komplex. Aber wenn ihr euch überlegt, wie viel Stress sowas ohne SQL wäre, ist das, finde ich, immer noch ganz elegant. Im echten Code kommt noch etwas Zusatzkomplexität dazu, weil ich Winkel interpolieren will und dabei immer die Frage ist, wie mensch die Identität von 360 und 0 Grad einrührt.
Eine vorsorgliche Warnung: aus der Art, wie ich den Spaltennamen hier reinfummele, folgt, dass, wer den Parameter kontrolliert, beliebiges SQL ausführen kann. Sprich: wer diesen Code irgendwie Web-zugänglich macht, darf keine unvalidierte Eingabe in col_name reinlassen.
Eingestandenermaßen ist diese Sorte von datenbankbasierter Interpolation nicht furchtbar effizient, aber für die 100000 Punkte, die ich im Augenblick plotten will, reicht es. Siehe: Den Code.
| [1] | Klar: Windrichtungen über Stunden linear zu interpolieren ist in den meisten Wetterlagen eher zweifelhaft. So, wie ich meine Plots mache, ist es aber nicht wesentlich verschieden davon, die Punkte über den Bereich zu verschmieren. Das wiederum wäre konzeptionell gar nicht so arg falsch. |