Im vergangenen Jahr habe ich meine CO₂-Messung am Balkon bis Mitte
September laufen lassen, vor allem, weil ich sehen wollte, wie die
Konzentrationen im Laufe der Zeit auf unter 300 ppm sinkt. So weit unten
(relativ zum gegenwärtigen globalen Mittelwert von um die 400 ppm) lag
zu meiner damaligen Überraschung die Konzentration mal ganz am Anfang
meiner CO₂-Messungen, im September 2021. Ich hatte eigentlich erwartet,
dass all das Grün im Sommer nach und nach auch in diesem Jahr dafür
sorgen würde.
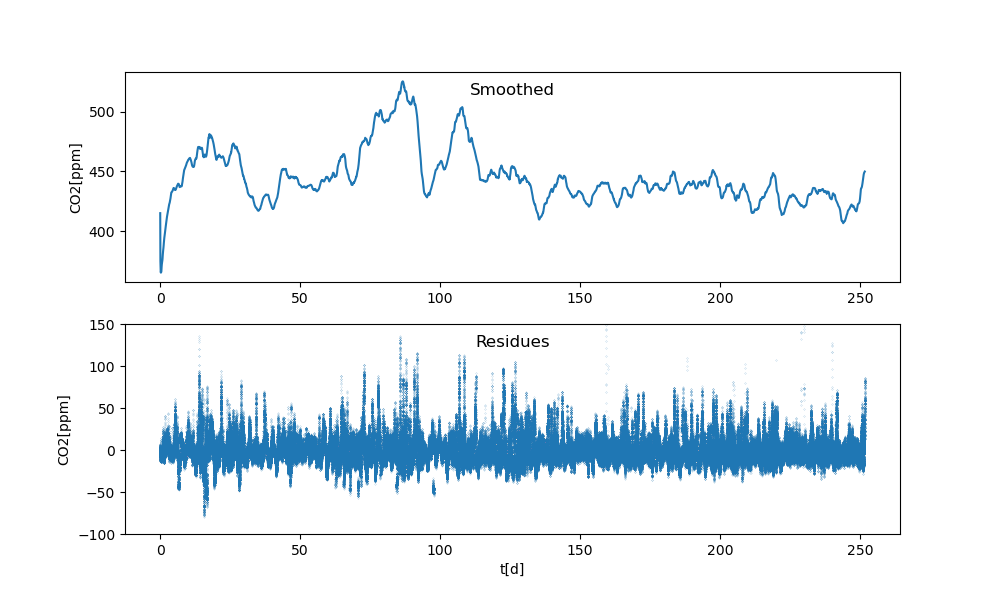
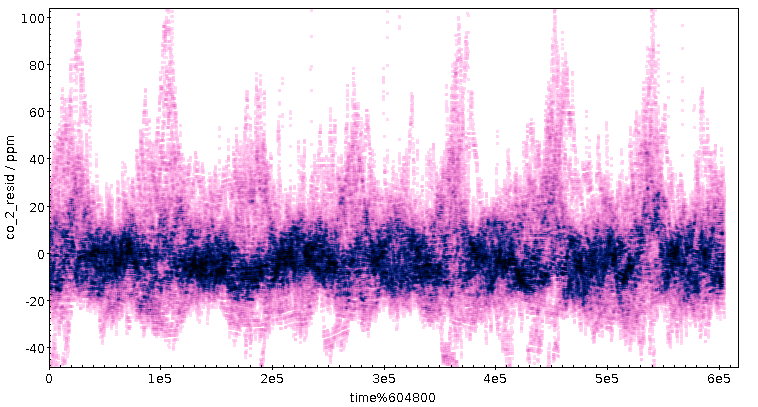
Daraus ist nichts geworden. Im Groben ist die CO₂-Konzentration über
Frühling und Sommer 2022 konstant geblieben:
(Alle Plots in diesem Post von TOPCAT). Mag sein, dass es einfach zu
trocken war in diesem Jahr – mag aber auch sein, dass meine ersten
Experimente einfach in besonders frischer Luft stattfanden. Schließlich
kämen natürlich noch Kalibrationsprobleme in Betracht; ich habe nicht
versucht, meine Messungen mit denen anderer zu abzugleichen.
Der Negativbefund hat mich aber dazu gebracht, die Daten im Hinblick auf
statistische und vor allem systematische Fehler genauer unter die Lupe
zu nehmen. Darum geht es in diesem Post.
Zunächst stellt sich die Frage, ob die generelle Zittrigkeit der Kurve
eigentlich Rauschen des Sensors ist oder etwas anderes – von Anfang an
haben mich ja die teils erheblichen Konzentrationsschwankungen
verblüfft. Nun: angesichts der hohen Korrelation benachbarter Messwerte
kommen diese jedenfalls nicht aus statistischen Fehlern im Sensor. Ich
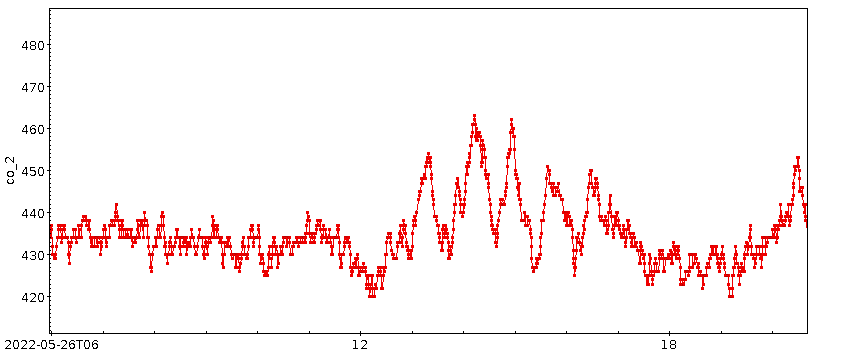
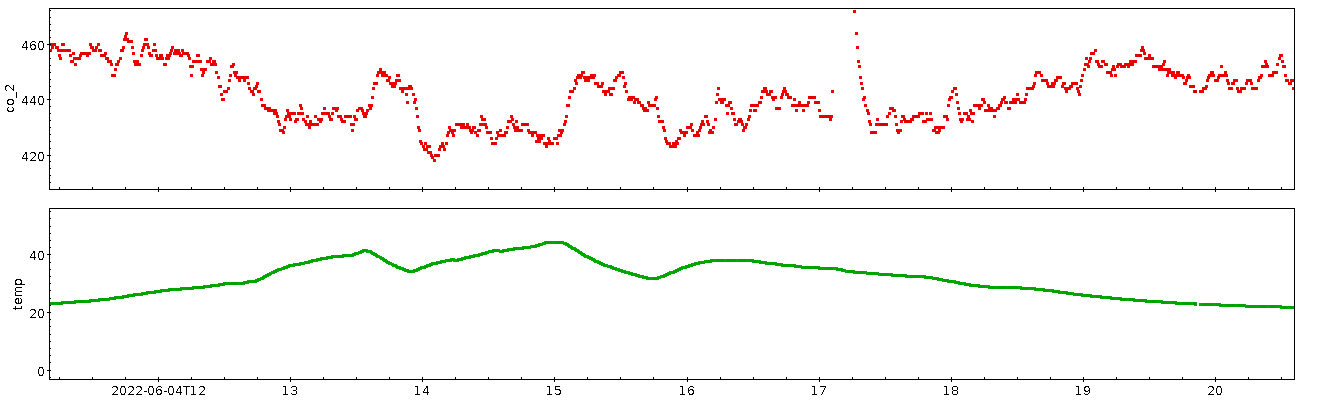
greife mal den 26. Mai (einen Donnerstag) heraus:
Wenn das Wackeln ein statistischer Fehler wäre, dann wäre die Linie, die
ich durch die Punkte gemalt habe, völliges Gekrakel und nicht
erkennbarer Verlauf. Ich will gerne glauben, dass da ein Rauschen
irgendwo unterhalb von 10 ppm drin ist. Der Rest ist irgendein
Signal.
Welcher Natur das Signal ist, ist eine Frage, die sich allenfalls mit
dem ganzen Datensatz beantworten lässt. Angesichts der überragenden
Bedeutung der Sonne für Physik und Leben auf der Erde geht der erste
Blick auf der Suche nach systematischen Fehlern oder auch echter
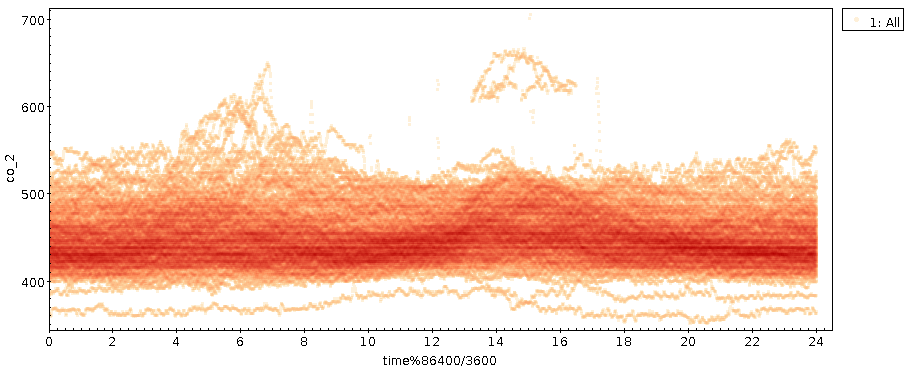
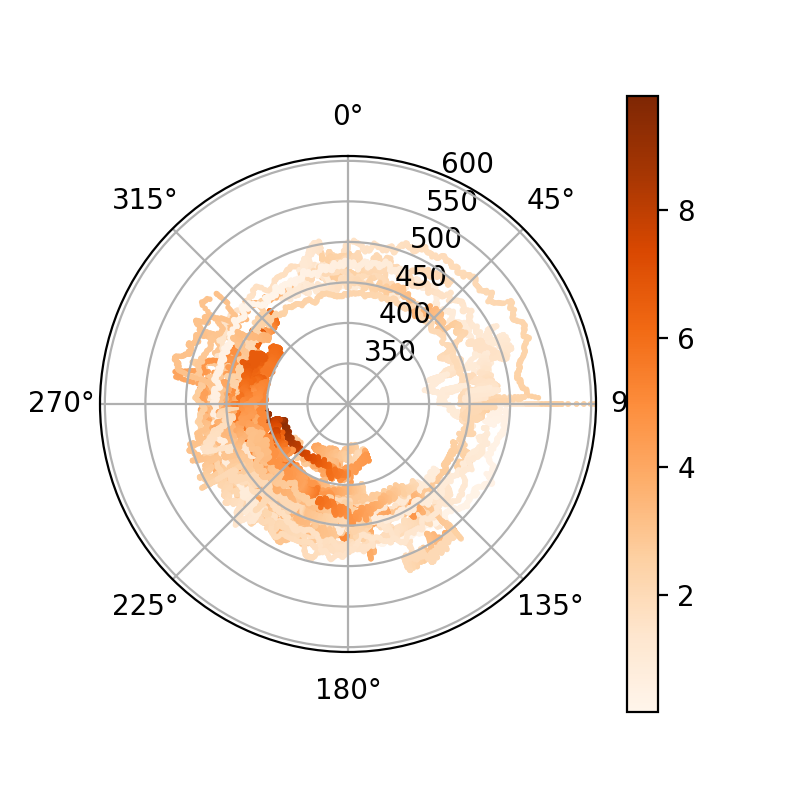
Physik bei solchen Zeitreihen erstmal auf die Tagesverläufe. Um da eine
Idee des Verhaltens des ganzen Datensatzes zu bekommen, habe ich mir die
Punktdichte in einem Plot von Tageszeit gegen CO₂-Konzentration
angesehen (ich „falte auf den Tag“):
Die Abszisse hier verdient einen kurzen Kommentar: Sie zeigt den Rest
bei der Division meiner Timestamps durch 84600, ausgedrückt in Stunden.
Meine Timestamps sind in Sekunden, und 84600 ist einfach 24 mal 3600,
also die Zahl der Sekunden an einem Tag. Mithin steht hier etwas
wie eine Tageszeit.
Ganz so einfach ist das aber nicht, weil meine Timestamps immer in UTC
laufen, während die Umgebung der Willkür der Zeitzonen unterworfen ist;
die 15 auf der Abszisse entspricht also manchmal 16 Uhr bürgerlicher
Zeit (nämlich, wenn die Umgebung MEZ hatte) und manchmal 17 Uhr (wenn
ihr Sommerzeit verordnet war). Aber schon rein optisch liegt nicht
nahe, dass viel mehr zu sehen wäre, wenn ich die politischen Kapriolen
nachvollziehen würde, um so weniger, als die Sonne die ja auch nicht
nachvollzieht.
Die Bäuche in der dunkleren Fläche, also einer besonders hohen Dichte
von Punkten, entsprechen nun Tageszeiten, zu denen es häufiger mal hohe
CO₂-Konzentrationen auf meinem Balkon gab. Das könnte ein Signal der
Lüftung unserer Wohnung (oder vielleicht sogar der unserer Nachbarn)
sein. Es ist aber auch plausibel, dass es der Reflex der Verkehrsdichte
ist. Der Balkon befindet sich etwa 10 Meter über und 20 Meter neben
einer recht viel befahrenen Straße, weshalb im September 2021 die
Unsichtbarkeit der CO₂-Emissionen der Fahrzeuge mit meine größte
Überraschung war. Mit hinreichend viel Statistik und Mitteln über
hinreichend viele Wetterlagen zeigen sich die Autos (vielleicht) eben
doch.
Wenn Effekte so sehr auf zusammengekniffenen Augen beruhen wie hier beim
Tagesverlauf, hilft es nichts: Da braucht es einen zweiten Blick auf
innere Korrelationen der Daten, um zu sehen, ob sich da schlicht
systematische Fehler zeigen oder ob es wirklich die Autos sind. Klar:
besser wäre es natürlich, mit bekannten Konzentrationen oder einfacher
einem bekannt guten Messgerät zu kalibrieren, also zu sehen, welche
Anzeige das Gerät für welchen wahren Wert hat.
Aber das ist aufwändig, und zumeist zeigen sich Systematiken mit ein
paar plausiblen Annahmen („Modelle“) auch schon in den Daten selbst.
Zur plausiblen Modellierung lohnt es sich, das Messprinzip des Geräts
zu betrachten. Der Sensor ist im Groben eine Infrarot-Leuchtdiode, die
in einem der Spektralbereiche sendet, in denen Kohlendioxid stark
absorbiert (weswegen es ja den Treibhauseffekt macht). Das Signal wird
dann von einer Fotodiode (oder etwas ähnlichem) aufgefangen, und die
Schwächung des Signals ist ein Maß für die Konzentration von CO₂
zwischen LED und Fotodiode.
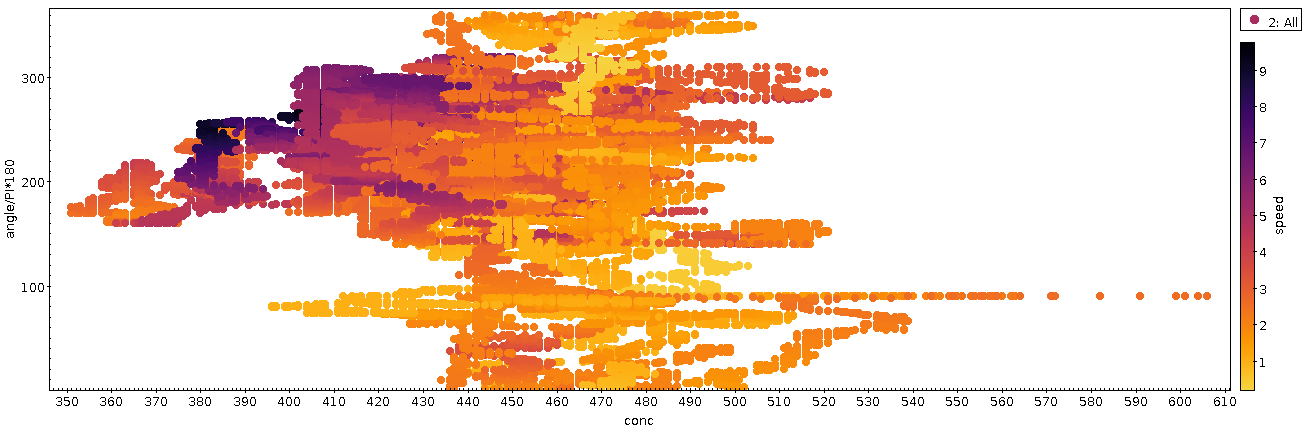
Allerdings sind alle Halbleiter temperaturempfindlich, und irgendwas,
das im Infrarotbereich empfängt, wird schon zwei Mal viel Kalibration
brauchen, um Temperatursystematik wegzukriegen. Mit Sicherheit tut die
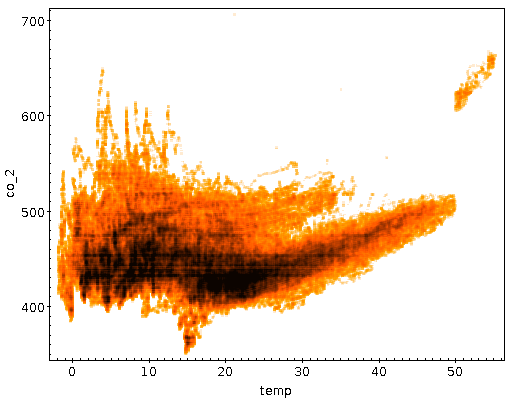
eingebaute Software schon viel in der Richtung. Aber ein Dichteplot
zwischen Temperatur und Konzentration zeigt durchaus einen ganzen Haufen
Struktur:
Manches davon ist ziemlich sicher Physik, so insbesondere, dass die ganz
hohen Konzentrationen bei niedrigen Temperaturen auftreten – das ist ein
Jahreszeiteneffekt. Anderes ist ganz klar Instrumentensignatur, am
klarsten das abgetrennte Schwanzende jenseits von 50 Grad
Sensortemperatur. Offenbar ist die Kalibrationskurve
(also: Welches Signal von der Fotodiode soll bei welcher Temperatur
welche CO₂-Konzentration ausgeben?) abschnittsweise definiert, und beim
Abschnitt über 50 Grad wird sich wohl wer bei den Hundertern vertippt
haben. Im Tagesplot entspricht dieses Schwänzchen übrigens dem
abgesetzten Häubchen am Nachmittag.
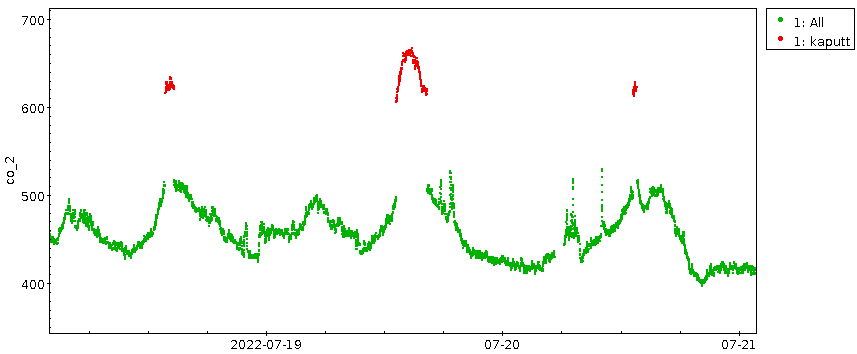
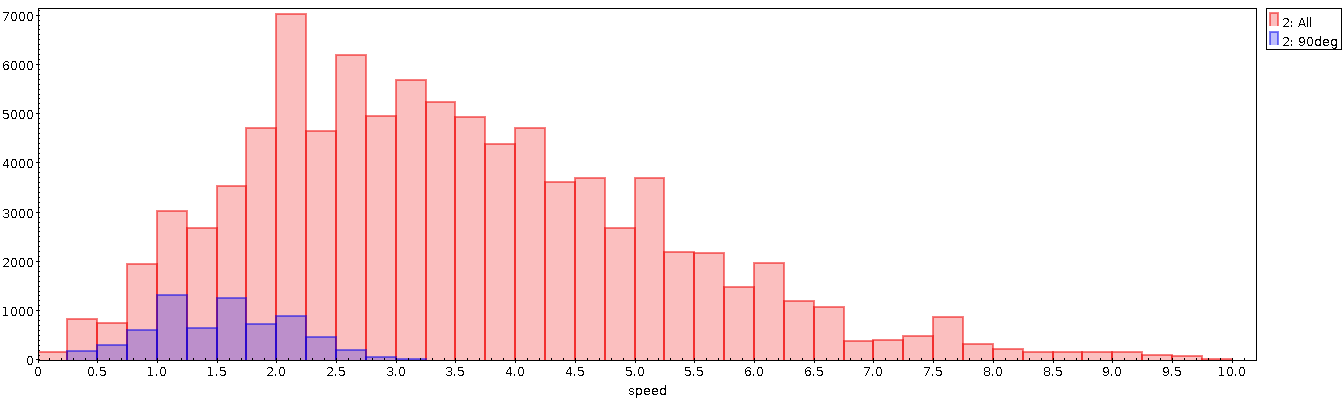
Im Neunmonatsplot zeigen sich die Punkte dort in ein paar der Spitzen
zwischen dem 18. Juli und dem 4. August, nur dass sie dort mit den
„normalen“ Daten mit einer Linie verbunden sind und nicht als abgesetzt
auffallen; Grundregel Nummer 312: Vorsicht beim Verbinden mit Linien. In
einem Scatterplot, bei dem Punkte in dem abgetrennten Schwanzende rot
gefärbt sind, sind die Unstetigkeiten (und mithin die Fehlkalibration
des Geräts) offensichtlich:
In meinem Datensatz betrifft das 1027 von 724'424 Datenpunkten –
eigentlich sollte ich die wegwerfen, aber wenn mensch einfach 100 von
ihnen abzieht, kommen weitgehend glatte Kurven raus, und so wird das
schon nicht völlig unvernünftig sein. Ich bin auch ganz glücklich mit
meiner Erklärung des Vertippers bei der Hunderterstelle der
abschnittsweise definierten Kalibrationskurve.
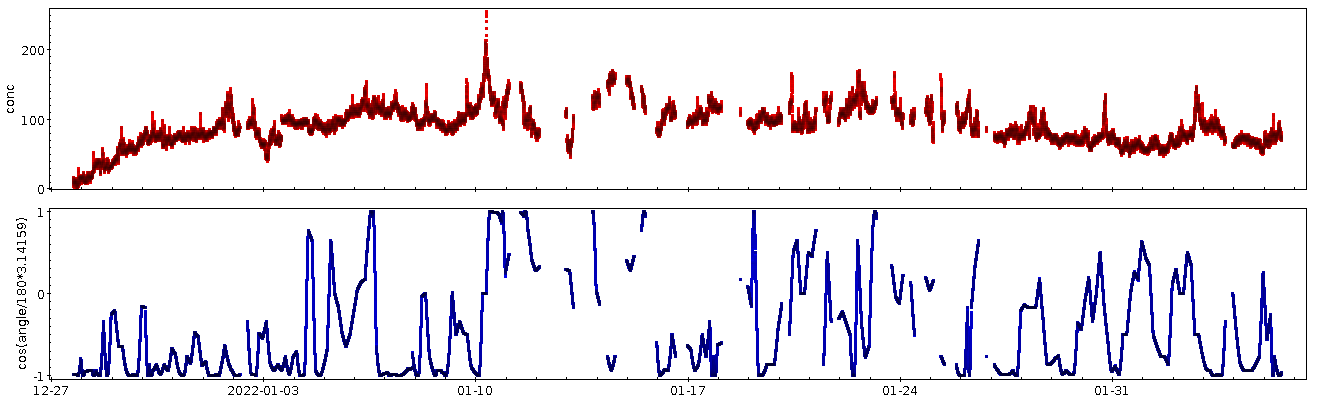
Mir gefällt aber auch die offensichtliche Korrelation von Temperatur und
CO₂ zwischen 30 und 50 Grad nicht, die sich in der „Fahne nach
Nordosten“ im T-Kalibrationsplot zeigt. Mein, na ja, Modell würde da
keine Korrelation, also einen ebenen Verlauf geradeaus „nach
Osten“ erwarten lassen.
Soweit das Modell zutrifft, ist die ganze Steigung nur eine weitere
Fehlkalibration der Temperaturabhängigkeit der Photodiode.
Mithin sollte mensch wahrscheinlich oberhalb von 30 Grad etwas wie
(T − 30) ⁄ 20⋅50 ppm (weil: über die 20 Grad
oberhalb von 30 Grad Celsius geht die Fahne um rund 50 ppm nach oben)
abziehen. Gegen Ende des Posts erwähne ich, warum ich die Korrektur am
Ende auf (T − 25) ⁄ 25⋅80 ppm erweitert habe.
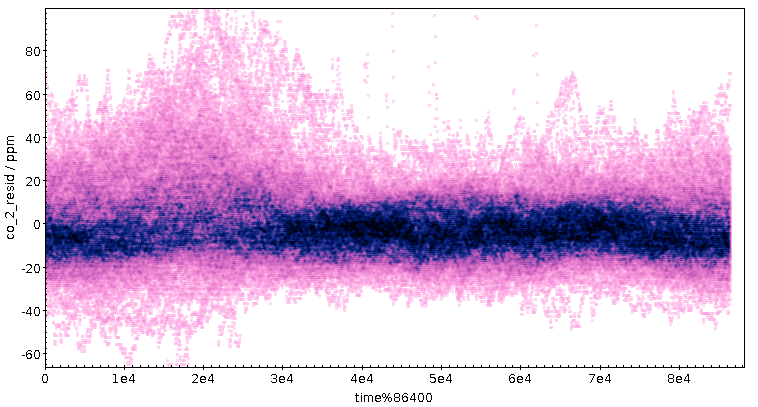
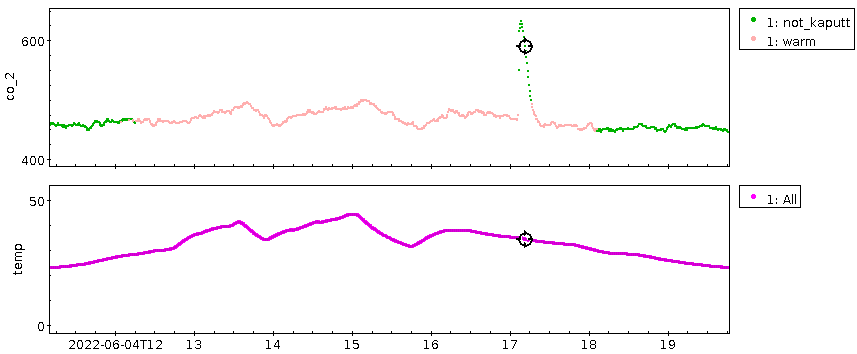
Zur näheren Untersuchung habe ich die Punkte aus der Fahne in einer
normalen CO₂-Zeitreihe rosa eingefärbt, die Temperatur dazugeplottet
und bin dabei zunächst auf ein Ereignis gestoßen, das mir sehr
merkwürdig vorkam:
Ich habe immer noch keine Ahnung, was hier passiert ist: Wenn nicht
einfach nur das Instrument durchgedreht ist, dann muss von irgendwoher
ein Schwung kohlendioxidreiche Luft gekommen sein, die aber an der
Temperatur unter der Eisdose nichts geändert hat. Wenn der Spike von
einer Wohnungslüftung käme, wäre das sehr seltsam, denn wenn die Leute
die Fenster zu hatten – und nur dann hätte sich CO₂ anreichern können –
wäre die Luft innen je nach Bauphysik fast sicher kühler oder wärmer
gewesen als draußen. Hm. Mein bestes Angebot: Luft ist ein schlechter
Wärmeleiter, und welches Lüftchen auch immer hier wehte, hat den
sonnenbeschienenen Sensor einfach nicht kühlen können.
Ach so: die Kurve ist beim Ergeignis grün, obwohl sich an der Temperatur
nichts geändert hat, weil bei den hohen CO₂-Konzentrationen die
ensprechenden Punkte aus der kleinen Nase über der Nordost-Fahne im
T-Kalibrationsplot zu liegen kommen. Pink ist aber nur gemalt, was
in der Fahne selbst ist.
Fruchtbarer ist die Betrachtung des parallelen Verlaufs von CO₂ und
Temperatur zwischen 13 und 16 Uhr. Diese Parallelität besteht
tatsächlich nur für die pinken Punkte. Es gibt keine plausible Physik,
die CO₂ und Temperatur (auf diesen Skalen) gleich schwingen lassen
würde. Wenn ich mit meiner Augenmaß-Kalibrationsfunktion von oben
korrigiere, verschwindet dieses Signal auch tatsächlich fast
vollständig:
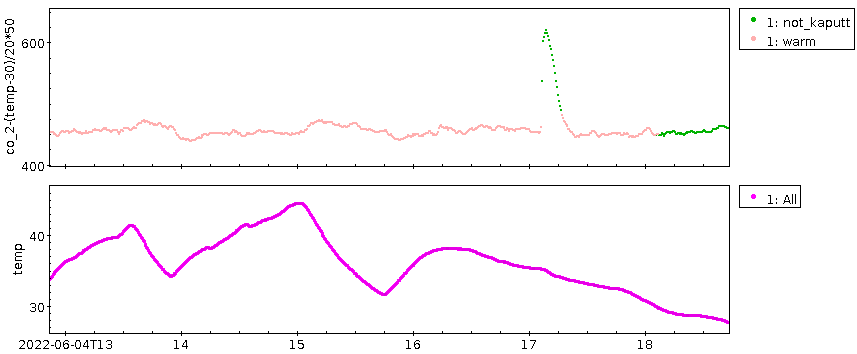
Beachtet die obere Achsenbeschriftung; das ist die Nachkalibration, die ich
zunächst angebracht habe; mit meiner verbesserten Nachkalibration ab
25°C bleibt etwas mehr Signal übrig:
Dass die Flanken des „Störsignals“ jetzt steiler sind, finde ich eher
beruhigend, denn ich glaube, dass das etwas mit direkter
Sonneneinstrahlung zu tun hat (die die Infrarotdiode ganz bestimmt
stört), und Licht und Schatten gehen natürlich viel schneller als die
Erwärmung von Luft und Gerät. In der Tat würde Streulicht von der Sonne
so tun, als käme etwas mehr Licht beim Sensor an, als wäre also etwas
weniger CO₂ im Strahlengang. Wenn ihr scharf schaut: im Plot sieht
es aus, als sei die CO₂-Schätzung niedriger, wenn die Temperatur
ansteigt (also vermutlich die Sonne schien) und höher, wenn sie das
nicht tat. Wäre das hier Wissenschaft, müsste ich dieser Spur genauer
nachgehen. So, wie es ist, kann …
![[RSS]](../theme/image/rss.png)







{kind=link}