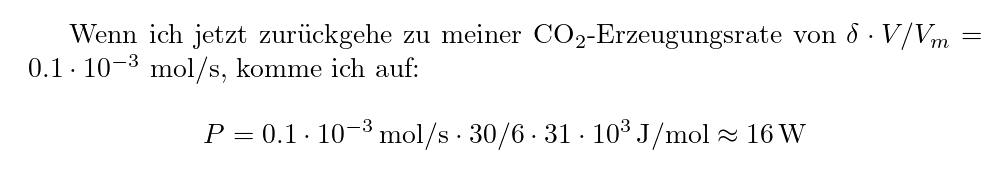Vor 10 Monaten habe ich den ersten Artikel für dieses Blog geschrieben, und
siehe da: Mit diesem sind es jetzt 100 Posts geworden.
Das wäre ein guter Vorwand für ein paar Statistiken, aber da ich ja
generell ein Feind von Metriken bin, die mensch ohne konkrete
Fragestellung sammelt (das ist ein wenig wie beim statistischen Testen:
Wenn du nicht von vorneherein weißt, worauf du testest, machst du es
falsch), bestätige ich mir nur, dass meine Posts viel länger sind als
ich das eigentlich will. Insgesamt nämlich habe ich nach Zählung von
wc -l auf den Quelldateien fast 93000 Wörter in diesen Artikeln.
Zur Fehlerabschätzung: xapian (vgl. unten) zählt nur 89000.
Die Länge der Artikel ist nach wc-Wörtern so verteilt:
Ich weiß auch nicht recht, warum ich mich nicht kürzer fassen kann.
Oder will. Der überlange Post mit 3244 Wörtern ist übrigens der über
die Konfiguration eines Mailservers – und das ist wieder ein gutes
Beispiel für die Fragwürdigkeit von Metriken, denn erstens hat Englisch
fast keine Komposita und ist von daher im Nachteil beim Wörterzählen und
zweitens ist in dem Artikel ziemlich viel Material, das in Wirklichkeit
Rechner lesen, und das sollte wirklich anders zählen als
natürlichsprachiger Text.
Na gut, und einem Weiteren kann ich nicht widerstehen: Wie viele
verschiedene Wörter („Paradigmata“) kommen da eigentlich vor? Das ist
natürlich auch Mumpitz, denn die Definition, wann zwei Wörter
verschieden sind („die Token verschiedenen Paradigmata angehören“), ist
alles andere als tivial. So würde ich beispielsweise behaupten, dass die
Wörter Worte und Wörter praktisch nichts miteinander zu tun haben,
während im Deuschen z.B. auf, schaute und aufschauen besser alle
zusammen ein einziges Paradigma bilden sollten (zusammen mit allerlei
anderem).
Aber ist ja egal, sind ja nur Metriken, ist also eh Quatsch. Und es
gibt die Daten auch schon, was für die Nutzung von und die Liebe zu
Kennzahlen immer ein Vorteil ist. Ich habe nämlich den xapian-Index über
dem Blog, und mit dem kann ich einfach ein paar Zeilen Python
schreiben:
import xapian
db = xapian.Database("output/.xapian_db")
print(sum(1 for w in db.allterms()))
(Beachtet die elegante Längenbestimmung mit konstantem Speicherbedarf –
db.allterms() ist nämlich ein Iterator).
Damit bekomme ich – ich stemme nach wie vor nicht – 16540 raus. Klar,
diese 16540 für die Zahl der verschiedenen Wörter ist selbst nach den
lockeren Maßstäben von Metriken ganz besonders sinnlos, weil es ja eine
wilde Mischung von Deutsch und Englisch ist.
Um so mehr Spaß macht es, das mit den 100'000 Wörtern zu vergleichen,
die schließlich mal im Goethe-Wörterbuch sein sollen, wenn es fertig
ist. Eine schnelle Webrecherche hat leider nichts zur Frage ergeben,
wie entsprechende Schätzungen für Thomas Mann aussehen. Einmal, wenn
ich gerne Kennzahlen vergleichen würde…
Aus dieser Kurve lässt sich ablesen, dass wir in acht Tagen knapp 3500
SARS-2-Fälle auf Intensivstationen haben werden. Wie, verrate ich in
diesem Artikel.
In meinen Corona-Überlegungen gestern habe ich mich mal wieder
gefragt, wie lange wohl die „Intensiv-Antwort“ dem Inzidenzsignal
nachläuft, wie viele Tage es also dauert, bis sich ein Anstieg in den
Inzidenzen in der Intensivbelegung reflektiert. Diese Frage ist, wie
ich unten ausführe, derzeit ziemlich relevant im Hinblick auf
Überlegungen, wie lange wir eigentlich noch Zeit haben, um massenhafte
Triage in (oder vor) unseren Intensivstationen abzuwenden.
Meine Null-Annahme für diese Verzögerung war seit Mai 2020 – nach einer
entsprechenden Ansage eines befreundeten Anästhesisten – „eher so drei
Wochen“. Bei nährem Nachdenken ist mir gestern aber aufgefallen, dass er
wohl eher „von Infektion bis Intensiv“ gemeint haben wird, und dann ist
die Antwort sicher schneller, denn von Infektion bis Meldung vergeht
normalerweise wohl mindestens eine Woche. Aber: Ich muss nicht
raten. Wir spielen hier mit Kennzahlen, die vielleicht in der Realität
nicht immer viel bedeuten, aber zumindest klar definiert sind. Daher
lässt sich der Verzug auf der Basis von RKI- und DIVI-Zahlen
nachrechnen.
Ich verrate gleich mal das Ergebnis: ich komme für die zweite Welle auf
gut fünf Tage Verzug der Intensiv-Antwort, für die dritte auf etwa
sieben Tage, für die vierte Welle auf acht bis neun Tage. Wie ich unten
ausführe, sind das relativ gute Nachrichten.
Zeitreihen
Wie habe ich das gerechnet? Nun, die Korrelation von Zeitreihen ist ein
ganzer Satz von Wissenschaften, bei denen es meist darum geht, ungleiche
Abdeckungen, unregelmäßig gesetzte Messpunkte sowie allerlei Rauschen und
Schmutz weggefummelt zu kriegen, ohne allzu viele Informationen zu
verlieren oder, vielleicht schlimmer, damit Artefakte einzubauen.
Die so gereinigten Daten lassen sich dann zum Beispiel geeignet skaliert
und verschoben übereinanderlegen. Tatsächlich sind die Parameter dieser
Transformationen im Regelfall (und gewissermaßen auch hier) viel
interessanter als die Zeitreihen selbst[1]. Es gibt daher
zahlreiche mathematische Verfahren, die das von einer Augenmaß-Übung in
etwas verwandeln, das reproduzierbar und auch quantifizierbar ist.
Vorsicht: ich bin da kein Experte und gehe hier nur mit nicht allzu
schwer erkranktem Menschenverstand ran, verwende also (zumindest in
Summe) gerade kein wirklich wohldurchdachtes Verfahren. Wer sowas wie
das hier für Hausaufgaben oder Hausarbeiten verwendet, tut das auf
eigene Gefahr.
Andererseits bin ich recht zuversichtlich, dass der Kram insgesamt schon
stimmt.
Ausgangsdaten sind meine aus RKI-Berichten gescrapten
Intensivbelegungen und ein RKI-Sheet (in, ach weh, „Office Open
XML“ a.k.a. XSLX – muss das sein?) mit den Inzidenzen. Dabei ist
das erste Problem, dass ich aus verschiedenen Gründen nicht für jeden
Tag Belegungszahlen habe, und so ist mein erster Schritt, fehlende
Punkte zu interpolieren. Das Scipy-Paket macht es leicht, aus einem
Satz von Zeit/Wert-Paaren (die Zeit wird in den Lesefunktionen auf
Sekunden seit einer Epoche gewandelt) ein handliches Array zu rechnen:
grid_points = numpy.arange(
raw_crits[0][0],
raw_crits[-1][0],
86400) # ein Tag in Sekunden
critnums = interpolate.griddata(
raw_crits[:,0], raw_crits[:,1], grid_points)
Ich wollte diese Interpolation eigentlich visualisieren, habe aber keine
gute Stelle gefunden, an der sie einen sichtbaren Unterschied
gemacht hätte, und entscheidend ist eigentlich nur, dass ich ab diesem
Schritt blind mit Arrays arbeiten kann; deren Index ist zunächst die
Zahl der Tage seit dem ersten Tag mit Daten, hier speziell dem
11.8.2020, denn damals habe ich mit dem Screenscrapen der DIVI-Daten
angefangen.
Übergeplottete Kurven
Wenn ich diese interpolierten Kurven übereinanderlege, kommt das hier
heraus:
Weil das, wie gesagt, erst im August 2020 anfängt, fehlt die erste
Welle.
Das bloße Auge reicht für die Bestätigung der Erwartung, dass die
Intensivbelegung der Inzidenzkurve meist etwas hinterherläuft, wenn auch
nicht so, dass mensch hoffen könnte, die beiden durch etwas Schieben
global übereinanderzubekommen. Die großen Zacken in den Inzidenzen
durch Weihnachten und Ostern finden sich in der Intensivbelegung
gar nicht wieder, was ein klares Zeichen ist, dass sie weitgehend
Erfassungsartefakte sind. In der Hinsicht wären die „großen“ RKI-Zahlen
mit Referenzdaten (vgl. die Film-Geschichte) bestimmt besser, aber
ich wollte für dieses Ding nicht die 200 Megabyte durchkämmen, zumal die
„kleinen“ RKI-Daten besser auf die Meldedaten aus den Tagesberichten
passen, um die es mir hier ja geht.
Vor allem fällt auf, dass meine Jammerei darüber, dass der
Impffortschritt die Intensivantwort nicht wesentlich abgeflacht hat,
unzutreffend ist: Mit der Skalierung aus dem Plot liegen Inzidenz und
Belegung in der zweiten und dritten Welle ziemlich übereinander, während
in der vierten Welle doch ein knapper Faktor zwei dazwischenliegt; da
scheint die Impfung doch ein wenig gegenüber Delta zu gewinnen (aber,
klar, nirgendwo hinreichend).
Ich hatte erwartet, dass die abfallenden Flanken der Intensivkurven
deutlich flacher sind als die der Inzidenzkurven, weil Leute unter
Umständen lang auf Intensiv liegen und es entsprechend lang dauern
sollte, bis sich die Stationen wieder leeren. Das sieht im Abfall der
zweiten Welle auch ein wenig so aus, nicht jedoch bei dem der dritten
Welle. Bei ihr fällt die Intensivbelegung sehr treu mit der Inzidenz.
So viele LangzeitpatientInnen gibt es glücklicherweise wohl doch nicht.
Nach Glätten differenzierbar
Wie kann ich jetzt den Verzug zu quantifizieren? Mein (wie gesagt eher
intuitiv gefasster) Plan ist, über die Ableitung der jeweiligen Kurven
zu gehen, und zwar aus der Überlegung heraus, dass mich ja Veränderungen
viel mehr als Pegel interessieren. Nun habe ich aber keine
differenzierbaren Funktionen, sondern lediglich Arrays, bei denen ich
Ableitungen allenfalls durch Subtrahieren benachbarter Elemente
simulieren kann. Solche numerischen „Ableitungen“ reagieren ziemlich
empfindlich auf das Gewackel („Rauschen“), das es in realen Daten immer
gibt („Subtraktion ist in der Regel numerisch schlecht konditioniert“).
Deshalb will ich meine rohen Daten glätten, bevor ich die „Ableitung“
ausrechne, sprich: das Rauschen rausnehmen, ohne das Signal wesentlich
zu verzerren.
Glättung heißt eigentlich immer, Kurvenpunkte in einem Zelle für Zelle
über die Daten laufenden Fenster zu mitteln, also z.B., indem mensch je
fünf Nachbarpunkte rechts und links auf den aktuellen Punkt draufaddiert
und ihn dann durch die durch elf geteilte Summe ersetzt. Mit diesem
ganz naiven Rezept bekommen relativ weit entfernte Werte aber genauso
viel Einfluss auf den aktuellen Punkt wie die unmittelbaren Nachbarn.
Das modelliert meist die sachlichen Grundlagen des Rauschens nur
schlecht. Es ist auch aus theoretischeren Gründen normalerweise eher
ungünstig.
Der eher theoretische Hintergrund ist grob, dass bei der Glättung
letztlich zwei Funktionen gefaltet werden. Das ist äquivalent dazu,
die Spektren der beiden Signale (ihre Fouriertransformierten) zu
multiplizieren und dann wieder zurückzutransformieren. Bei einem
einfachen Fenster des oben skizierten Typs („Rechteckfunktion“) gibts
nun sehr scharfe Kanten, die wiederum zu einem sehr breiten Spektrum
führen, so dass auch das Spektrum der geglätteten Funktion allerlei
unwillkommene Features bekommen kann (manchmal ist das aber auch genau
das, was mensch haben will – hier nicht).
Wie auch immer: scipy macht es einfach, mit einer lärmarmen Funktion –
die sieht ein wenig gaußig aus und ist im nächsten Plot im kleinen Inset
zu sehen – zu glätten, nämlich etwa so:
import numpy
from scipy import signal
smoothing_kernel = numpy.kaiser(20, smoothing_width)
smoothing_kernel = smoothing_kernel/sum(smoothing_kernel)
convolved = signal.convolve(arr, smoothing_kernel, mode="same"
)[smoothing_width:-smoothing_width]
Die Division durch die Summe von smoothing_kernel in der zweiten
Zeile sorgt dafür, dass sich an der „Höhe“ der geglätteten Funktion
insgesamt nichts ändert: Sozusagen ausgeklammert ist die Faltung eine
Multiplikation mit eins. Das Wegschneiden der Ränder in der letzten
Zeile wiederum entfernt Punkte, bei denen fehlende Werte am Anfang und
Ende der Zeitreihe im Fenster waren. Scipy ersetzt die durch Nullen, so
dass die geglätteten Werte am Rand steil abfallen. Was ich hier mache,
entspricht technisch dem valid-Mode der convolve-Funktion. Nur weiß ich
hier zuverlässig, wie lang das Array am Schluss ist.
Der Effekt, hier auf Indzidenzdaten der vierten Welle:
Damit kann ich jetzt meine numerische „Ableitung“ bilden, ohne dass mir
das Ergebnis furchtbar rauscht:
diff = convolved[1:]-convolved[:-1]
Die nächsten beiden Grafiken zeigen diese Pseudo-Ableitungen für
Inzidenz und Intensivbelegung. Ich habe jeweils in blau reingemalt, wie
es ohne Glättung aussehen würde, um deutlich zu machen, warum diese eine
gute Idee ist und was ich mit „furchtbar rauschen“ meine.
Weiterverwendet werden natürlich die orangen Verläufe:
In der Inzidenzkurve fallen wieder Weihnachten und Ostern besonders auf,
weil sie selbst in den geglätteten Graphen noch wilde Ausschläge
verursachen.
In der Zeit verschieben
Schon der optische Eindruck aus dem Rohdaten-Plot legt nahe, die
einzelnen Wellen getrennt zu untersuchen, und das ist angesichts von
über die Zeit stark veränderlichen Viren, Testverhältnissen,
demographischen Gegebenheiten und nichtpharamzeutischen Maßnahmen sicher
auch sachlich geboten.
Deshalb hier zunächst der Verlauf der Ableitungen von Inzidenzen und
Intensivbelegung in der aktuellen vierten Welle (das ist eine
Kombination der rechten Enden der orangen Graphen der letzten beiden
Plots):
In dem Graphen steckt noch eine weitere Normalisierung. Und zwar habe
ich für beide Arrays etwas wie:
incs /= sum(abs(incs))
laufen lassen. Damit ist die Fläche zwischen den Kurven …
As the number of posts on this blog approaches 100, I figured some sort
of search functionality would be in order. And since I'm wary of “free”
commercial services and Free network search does not seem to go
anywhere[1], the only way to offer that that is both practical and
respectful of the digital rights of my readers is to have a local search
engine. True, having a search engine running somewhat defeats the
purpose of a static blog, except that there's a lot less code necessary
for doing a simple search than for running a CMS, and of course you
still get to version-control your posts.
I have to admit that the “less code” argument is a bit relative given
that I'm using xapian as a full-text indexer here. But I've long wanted
to play with it, and it seems reasonably well-written and
well-maintained. I have hence written a little CGI script enabling
search over static collections of HTML files, which means in particular
pelican blogs. In this post, I'll tell you first a few things about how
this is written and then how you'd run it yourself.
Using Xapian: Indexing
At its core, xapian is not much more than an inverted index:
Essentially, you feed it words (“tokens”), and it will generate a
database pointing from each word to the documents that contain it.
The first thing to understand when using xapian is that it doesn't
really have a model of what exactly a document is; the example indexer
code, for instance, indexes a text file such that each paragraph is
treated as a separate document. All xapian itself cares about is a
string („data“, but usually rather metadata) that you associate with a
bunch of tokens. This pair receives a numeric id, and that's it.
There is a higher-level thing called omega built on top of xapian that
does identify files with xapian documents and can crawl and index a whole
directory tree. It also knows (to some extent) how to pull tokens from
a large variety of file types. I've tried it, and I wasn't happy; since
pelican creates all those ancillary HTML files for tags, monthly
archives, and whatnot, when indexing with omega, you get lots of really
spurious matches as soon as people enter a term that's in an article
title, and entering a tag or a category will yield almost all the files.
So, I decided to write my own indexer, also with a view to later
extending it to language detection (this blog has articles in German and
English, and they eventually should be treated differently). The core
is rather plain in Python:
for dir, children, names in os.walk(document_dir):
for name in fnmatch.filter(names, "*.html"):
path = os.path.join(dir, name)
doc = index_html(indexer, path, document_dir)
That's enough for iterating over all HTML files in a pelican output
directory (which document_dir should point to).
In the code, there's a bit of additional logic in the do_index
function. This code enables incremental indexing, i.e., only re-indexing a
file if it has changed since the last indexing run (pelican fortunately
manages the file timestamps properly).
What I had to learn the hard way
is that since xapian has no built-in relationship between what it
considers a document and an operating system file, I need to explicitly
remove the previous document matching a particular file. The function
get_indexed_paths produces a suitable data structure for that
from an existing database.
The indexing also defines my document model; as said above, as
far as xapian is concerned, a document is just some (typically metadata)
string under user control (plus the id and the tokens, obviously).
Since I want structured metadata, I need to structure that string, and
these days, json is the least involved thing to have structured data in
a flat string. That explains the first half of the function that
actually indexes one single document, the path of which comes in in
f_name:
def index_html(indexer, f_name, document_dir):
with open(f_name, encoding="utf-8") as f:
soup = bs4.BeautifulSoup(f, "lxml")
doc = xapian.Document()
meta = {
"title": soup_to_text(soup.find("title")),
"path": remove_prefix(f_name, document_dir),
"mtime": os.path.getmtime(f_name),}
doc.set_data(json.dumps(meta))
content = soup.find(class_="indexable")
if not content:
# only add terms if this isn't some index file or similar
return doc
print(f"Adding/updating {meta['path']}")
indexer.set_document(doc)
indexer.index_text(soup_to_text(content))
return doc
– my metadata thus consists of a title, a path relative to pelican's
output directory, and the last modification time of the file.
The other tricky part in here is that I only index children of the first
element with an indexable class in the document. That's the key to
keeping out all the tags, archive, and category files that pelican
generates. But it means you will have to touch your templates if you
want to adopt this to your pelican installation (see below). All other
files are entered into the database, too, in order to avoid needlessly
re-scanning them, but no tokens are associated with them, and hence they
will never match a useful query.
Nachtrag (2021-11-13)
When you add the indexable class to your, also declare the language in
order to support stemming; this would look like lang="{{ page.lang
}} (substituting article for page as appropriate).
There is a big lacuna here: the recall, i.e., the ratio between the
number of documents actually returned for a query and the number of
documents that should (in some sense) match, really suffers in both
German and English if you don't do stemming, i.e., fail to strip off
grammatical suffixes from words.
Stemming is of course highly language-dependent. Fortunately,
pelican's default metadata includes the language. Less fortunately, my
templates don't communicate that metadata yet – but that would be quick
to fix. The actual problem is that when I stem my documents, I'll also
have to stem the incoming queries. Will I stem them for German or for
English?
I'll think about that problem later and for now don't stem at all; if
you remember that I don't stem, you can simply append an asterisk to
your search term; that's not exactly the same thing, but ought to be
good enough in many cases.
Using xapian: Searching
Running searches using xapian is relatively straightforward: You open
the database, parse the query, get the set of matches and then format
the metadata you put in during indexing into links to the matches. In
the code, that's in cgi_main; one could do paging here, but I
figure spitting out 100 matches will be plenty, and distributing 100
matches on multiple HTML pages is silly (unless you're trying to
optimise your access statistics; since I don't take those, that doesn't
apply to me).
The part with the query parser deserves a second look, because xapian
supports a fairly rich query language, where I consider the most useful
features:
Phrase searches ("this is a phrase")
Exclusions (-dontmatch)
Matches only when two words appear within 10 tokens of each other
(matches NEAR appear)
Trailing wildcard as in file patterns (trail*)
That last feature needs to be explicitly enabled, and since I find it
somewhat unexpected that keyword arguments are not supported here, and
perhaps even that the flag constant sits on the QueryParser object,
here's how enabling wildcards in xapian looks in code:
You can re-use my search script on your site relatively easily.
It's one file, and if you're running an apache or something else that
can run CGIs[2], making it run first is close to trivial: Install
your equivalents of the Debian python3-xapian, python3-bs4, and
python3-lxml packages. Perhaps you also need to explicitly allow CGI
execution on your web server. In Debian's apache, that would be
a2enmod cgi, elsewhere, you may need to otherwise arrange for
mod_cgi or its equivalent to be loaded.
Then you need to dump blogsearch somewhere in the file system.
While Debian has a default CGI directory defined, I'd suggest to put
blogsearch somewhere next to your blog; I keep everything together in
/var/blog (say), have the generated output in
/var/blog/generated and would then keep the script in a directory
/var/blog/cgi. Assuming this and apache, You'd then have something
like:
in your configuration, presumably in a VirtualHost definition. In
addition, you will have to tell the script where your pelican directory
is. It expects that information in the environment variable
BLOG_DIR; so, for apache, add:
SetEnv BLOG_DIR /var/blog/generated
to the VirtualHost.
After restarting your web server, the script would be ready
(with the configuration above …
I recently wrote a piece on estimating my power output from CO₂
measurements (in German) and for the first time in this blog needed to
write at least some not entirely trivial math. Well: I was seriously
unhappy with the way formulae came out.
Ugly math of course is very common as soon as you leave the lofty realms
of LaTeX. This blog is made with ReStructuredText (RST) in pelican.
Now, RST at least supports the math interpreted text role
(“inline”) and directive (“block“ or in this case rather “displayed“)
out of the box. To my great delight, the input syntax is a subset of
LaTeX's, which remains the least cumbersome way to input typeset math
into a computer.
But as I said, once I saw how the formulae came out in the browser,
my satifsfaction went away: there was really bad spacing, fractions
weren't there, and things were really hard to read.
In consequence, when writing the post I'm citing above, rather than
reading the docutils documentation to research whether the ugly
rendering was a bug or a non-feature, I wrote a footnote:
Sorry für die hässlichen Formeln. Vielleicht schreibe ich mal eine
Erweiterung für ReStructuredText, die die ordentlich mit TeX
formatiert. Oder zumindest mit MathML. Bis dahin: Danke für euer
Verständnis.
(Sorry for the ugly formulae. Perhaps one of these days I'll write
an RST extension that properly formats using TeX. Or at least MathML.
Until then: thanks for your understanding.)
This is while the documentation clearly said, just two lines below
the example that was all I had initially bothered to look at:
For HTML, the math_output configuration setting (or the corresponding
--math-output command line option) selects between alternative output
formats with different subsets of supported elements.
Following the link at least would have told me that MathML was already
there, saving me some public embarrassment.
Anyway, when yesterday I thought I might as well have a look at whether
someone had already written any of the code I was talking about in the
footnote, rather than properly reading the documentation I started
operating search engines (shame on me).
Only when those lead me to various sphinx and pelican extensions and I
peeked into their source code I finally ended up at the docutils
documentation again. And I noticed that the default math rendering was
so ugly just because I didn't bother to include the math.css
stylesheet. Oh, the miracles of reading documentation!
With this, the default math rendering suddenly turns from ”ouch” to
“might just do”.
But since I now had seen that docutils supports MathML, and since I have
wanted to have a look at it at various times in the past 20 years, I
thought I might as well try it, too. It is fairly straightforward
to turn it on; just say:
[html writers]
math_output: MathML
in your ~/.docutils (or perhaps via a pelican plugin).
I have to say I am rather underwhelmed by how my webkit renders it.
Here's what the plain docutils stylesheet works out to in my current
luakit:
And here's how it looks like via MathML:
For my tastes, the spacing is quite a bit worse in the MathML case;
additionally, the Wikipedia article on MathML mentions that the Internet
Explorer never supported it (which perhaps wouldn't bother me too much)
and that Chromium withdrew support at some point (what?). Anyway: plain
docutils with the proper css is the clear winner here in my book.
I've not evaluated mathjax, which is another option in docutils
math_output and is what pelican's render_math plugin uses. Call me a
luddite, but I'll file requiring people to let me execute almost
arbitrary code on their box just so they see math into the big folder
labelled “insanities of the modern Web”.
So, I can't really tell whether mathjax would approach TeX's quality,
but the other two options clearly lose out against real TeX, which
using dvipng would render the example to:
– the spacing is perfect, though of course the inline equation has a
terrible break (which is not TeX's fault). It hence might still be
worth hacking a pelican extension that collects all formulae, returns
placeholder image links for them and then finally does a big dvipng run
to create these images. But then this will mean dealing with a lot of
files, which I'm not wild about.
What I'd like to ideally use for the small PNGs we are talking about here
would be inline images using the data scheme, as in:
<img src="data:image/png;base64,AAA..."/>
But since I would need to create the data string when docutils calls my
extension function, I in that scheme cannot collect all the math
rendering for a single run of LaTeX and dvipng. That in turn would mean
either creating a new process for TeX and dvipng each for each piece of
math, which really sounds bad, or hacking some wild pipeline involving
both, which doesn't sound like a terribly viable proposition either.
While considering this, I remembered that matplotlib renders quite a bit
of TeX math strings, too, and it lets me render them without any
fiddling with external executables. So, I whipped up this piece of
Python:
import base64
import io
import matplotlib
from matplotlib import mathtext
matplotlib.rcParams["mathtext.fontset"] = "cm"
def render_math(tex_fragment):
"""returns self-contained HTML for a fragment of TeX (inline) math.
"""
res = io.BytesIO()
mathtext.math_to_image(f"${tex_fragment}$",
res, dpi=100, format="png")
encoded = base64.b64encode(res.getvalue()).decode("ascii")
return (f'<img src="data:image/png;base64,{encoded}"'
f' alt="{tex_fragment}" class="math-png"/>')
if __name__=="__main__":
print(render_math("\int_0^\infty \sin(x)^2\,dx"))
This prints the HTML with the inline formula, which with the example
provided looks like this:
– ok, there's a bit too much cropping, I'd have to trick in transparency,
there's no displayed styles as far as I can tell, and clearly one would
have to think hard about CSS rules to make plausible choices for scale
and baseline – but in case my current half-satisfaction with docutils'
text choices wears off: This is what I will try to use in a docutils
extension.
Wer solche Bingo-Karten haben will: Das Wahlbingo-CGI macht sie euch
gerne. Jeder Reload macht neue Karten!
Auch wenn verschiedenePosts der letzten Zeit etwas anderes
suggerieren mögen: Ich will gewiss nicht in die von Plakatwänden und aus
Radiolautsprechern quellende Wahlaufregung einstimmen. Aber ein wenig
freue ich mich doch auf die Bundestagswahl am nächsten Sonntag: ich kann
nämlich wieder mein Wahlbingo spielen. Ihr kriegt bei jedem Reload
der Bingo-Seite andere Karten, und zumindest Webkit-Browser sollten das
auch so drucken, dass auf einer A4-Seite zwei Bingokarten rauskommen.
Die Regeln sind dabei: Wer in der Wahlkampfberichterstattung eine
hinreichend ähnliche Phrase aufschnappt, darf ein Feld abkreuzen (die
Hälfte vom Spaß ist natürlich die lautstarke Klärung der Frage, ob eine
Phrase ähnlich genug war). Wer zuerst vier…
Nachtrag (2022-03-07)
Die Erfahrung zeigt, dass es mit drei mehr Spaß macht.
…Felder in horizonaler,
vertikaler, oder diagonaler Richtung hat, hat gewonnen. Dabei gelten
periodische Randbedingungen, mensch darf also über den Rand hinaus
verlängern, als würde die eigene Karte die Ebene parkettieren.
Das Ganze ist übrigens ein furchtbar schneller Hack an irgendeinm
Wahlabend gewesen. Ich habe den gerade noch geschwinder für das Blog in
ein CGI gewandelt. Wer darauf etwas Aufgeräumteres aufbauen will: die
Quellen. Spenden für den Phrasenkorpus nehme ich sehr gerne per Mail.
Last weekend I had my first major in-person conference since the SARS-2
pandemic began: about 150 people congregated from all over Germany to
quarrel and, more importantly, to settle quarrels. But it's still
Corona, and thus the organisers put in place a whole bunch of disease
control measures. A relatively minor of these was monitoring the CO2
levels in the conference hall as a proxy for how much aerosol may have
accumulated. The monitor devices they got were powered by USB, and
since I was sitting on the stage with a computer having USB ports
anyway, I was asked to run (and keep an eye on) the CO2 monitor for
that area.
The CO2 sensor I got my hands on. While it registers as a Holtek
USB-zyTemp, on the back it says “TFA Dostmann Kat.Nr. 31.5006.02“. I
suppose the German word for what's going on here is
“Wertschöpfungskette“ (I'm not making this up. The word, I mean. Why
there are so many companies involved I really can only guess).
When plugging in the thing, my syslog[1] intriguingly said:
usb 1-1: new low-speed USB device number 64 using xhci_hcd
usb 1-1: New USB device found, idVendor=04d9, idProduct=a052, bcdDevice= 2.00
usb 1-1: New USB device strings: Mfr=1, Product=2, SerialNumber=3
usb 1-1: Product: USB-zyTemp
usb 1-1: Manufacturer: Holtek
usb 1-1: SerialNumber: 2.00
hid-generic 0003:04D9:A052.006B: hiddev96: USB HID v1.10 Device [Holtek USB-zyTemp] on usb-0000:00:14.0-1/input0
hid-generic 0003:04D9:A052.006C: hiddev96: USB HID v1.10 Device [Holtek USB-zyTemp] on usb-0000:00:14.0-1/input0
So: The USB is not only there for power. The thing can actually talk
to the computer. Using the protocol for human interface devices (HID,
i.e., keyboards, mice, remote controls and such) perhaps is a bit funky
for a measurement device, but, on closer reflection, fairly reasonable:
just as the mouse reports changes in its position, the monitor reports
changes in CO2 levels and temperatures of the air inside of it.
Asking Duckduckgo for the USB id "04d9:a052" (be sure to make it a phrase
search with the quotes our you'll be bombarded by pages on bitcoin
scams) yields a blog post on decrypting the wire protocol and, even
better, a github repo with a few modules of Python to read out values
and do all kinds of things with them.
However, I felt like the amount of code in that repo was a bit
excessive for something that's in the league of what I call a classical
200 lines problem – meaning: a single Python script that works without
any sort of installation should really do –, since all I wanted (for
now) was a gadget that shows the current values plus a bit of history.
Hence, I explanted and streamlined the core readout code and added some
100 lines of Tkinter to produce co2display.py3, showing an interface
like this:
This is how opening a window (the sharp drop of the curve on the
left), then opening a second one (the even sharper drop following)
and closing it again while staying in the room (the gentle slope on
the right) looks like in co2display.py. In case it's not obvious: The
current CO2 concentration was 420 ppm, and the temperature 23.8
degrees Centigrade (where I'm sure the thing doesn't measure to
tenths of Kelvins; but then who cares about thenths of Kelvins?) when
I took that screenshot.
If you have devices like the zyTemp yourself, you can just download the
program, install the python3-hid package (or its equivalent on
non-Debian boxes) and run it; well, except that you need to make sure
you can read the HID device nodes as non-root. The easiest way to do
that is to (as root) create a file
/etc/udev/rules.d/80-co2meter.rules containing:
This udev rule simply says that whenever a device with the respective
ids is plugged in, any device node created will be world-readable and
world-writable (and yeah, it does over-produce a bit[2]).
After adding the rule, unplug and replug the device and then type
python3 co2display.py3. Ah, yes, the startup (i.e., the display
until actual data is available) probably could do with a bit of extra
polish.
First Observations
I'm rather intrigued by the dynamics of CO2 levels measured in that
way (where I've not attempted to estimates errors yet). In reasonably
undisturbed nature at the end of the summer and during the day, I've
seen 250 to 280 ppm, which would be consistent with mean global
pre-industrial levels (which Wikipedia claims is about 280 ppm). I'm
curious how this will evolve towards winter and next spring, as I'd
guess Germany's temporal mean will hardly be below the global one of a
bit more than 400 (again according to Wikipedia).
In a basically empty train I've seen 350 ppm yesterday, a slightly
stuffy train about 30% full was at 1015 ppm, about as much as I have in
my office after something like an hour of work (anecdotically, I think
half an hour of telecon makes for a comparable increase, but I can
hardly believe that idle chat causes more CO2 production than
heavy-duty thinking. Hm).
On a balcony 10 m above a reasonably busy road (of order one car every
10 seconds) in a lightly built-up area I saw 330 ppm under mildly
breezy conditions, dropping further to 300 as the wind picked up.
Surprisingly, this didn't change as I went down to the street level.
I can hardly wait for those winter days when the exhaust gases are
strong in one's nose: I cannot imagine that won't be reflected in the
CO2.
The funkiest measurements I made on the way home from the meeting that
got the device into my hands in the first place, where I bit the bullet
and joined friends who had travelled their in a car (yikes!). While
speeding down the Autobahn, depending on where I measured in the small
car (a Mazda if I remember correctly) carrying four people, I found
anything from 250 ppm near the ventilation flaps to 700 ppm around my
head to 1000 ppm between the two rear passengers. And these values were
rather stable as long as the windows were closed. Wow. Air flows in
cars must be pretty tightly engineered.
Technics
If you look at the program code, you'll see that I'm basically
polling the device:
– that's how I usually do timed things in tkinter programs, where, as
normal in GUI programming, there's an event loop external to your code
and you cannot just say something like time.wait() or so.
Polling is rarely pretty, but it's particularly inappropriate in this
case, as the device (or so I think at this point) really sends data as
it sees fit, and it clearly would be a lot better to just sit there and
wait for its input. Additionally, _take_sample, written as it is,
can take quite a bit of time, and during that time the UI is
unresponsive, which in this case means that resizes and redraws don't
take place.
That latter problem could easily be fixed by pushing the I/O into a
thread. But then this kind of thing is what select was invented
for, or, these days, wrappers for it (or rather its friends) usually
subsumed under “async programming“.
However, marrying async and the Tkinter event loop is still painful, as
evinced by this 2016 bug against tkinter. It's still open. Going
properly async on the CO2monitor class in the program will still be
the next thing to do, presumably using threads.
Ah, that, and recovering from plugging the device out and in again,
which would also improve behaviour as people suspend the machine.
Apart from that, there's just one detail I should perhaps highlight in
the code: The
in the constructor. That makes the history plot re-scale if the UI is
re-sized, and I've always found it a bit under-documented that
<Configure> is the event to listen for in this situation. But
perhaps that's just me.
Nachtrag (2021-10-19)
I've updated co2display.py3 as published here, since I've been
hacking on it quite a bit in the meantime. In particular, if you
rename the script co2log.py (or anything else with “log” in it), this
will run as a plain logger (logging into /var/log/co2-levels by
default), and there's a systemd unit at the end of the script that
lets you run this automatically; send a HUP to the process to make it
re-open its log; this may be useful together with logrotate if you let
this run for weeks your months.
You can also enable logging while letting the Tk UI run by passing a
-d option …
Am Ende meines Posts zum Corona-Inzidenzfilm hatte ich
zuversichtlich gesagt, der RKI-Datensatz gebe durchaus auch Plots von
Altersmedianen her. Tja… da habe ich den Mund etwas zu voll
genommen, denn was wirklich drinsteht, sind Altersgruppen, und die sind
so grob, dass eine halbwegs seriöse Schätzung hinreichend dekorativer
(also: mit mindestens 256 verschiedenen Werten) Mediane
doch einige Überlegung erfordert.
Die Altersgruppen reichen aber auch ohne Sorgfalt, um eine Art Score
auszurechnen (ich verrate gleich, wie ich das gemacht habe), und damit
ergibt sich zum Beispiel dieser Film:
Nur damit sich niemand wundert, wie Herbst-Zahlen in einen Post vom
August kommen: Ich habe den Film bis November 2021 fortgesetzt und
werde ihn künftig wohl noch ein paar Mal aktualisieren.
Was ist da zu sehen? Die Farbskala gibt etwas, das ich Alters-Score
genannt habe. Dabei habe ich die Altersgruppen aus den RKI-Daten so in
Zahlen übersetzt:
A00-A04
2
A05-A14
10
A15-A34
20
A35-A59
47
A60-A79
70
A80+
85
unbekant
ignoriert
Das, was dabei rauskommt, mittele ich für alle berichteten Fälle
innerhalb von 14 Tagen. Die robustere und ehrlichere Alternative wäre
wahrscheinlich, da einen interpolierten Median auszurechnen, aber das
habe ich schon deshalb gelassen, weil ich dann möglicherweise eine obere
Grenze bei A80+ hätte annehmen müssen; so, wie es ist, ist es allenfalls
ein Score, dessen Vergleichbarkeit zwischen Kreisen angesichts
wahrscheinlich recht weit auseinanderliegender Altersverteilungen so
la-la ist. Mehr Substanz als Uni- oder Mensarankings hat er aber auf
jeden Fall (was kein starker Claim ist).
Wirklich fummelig an dieser Visualisierung war, dass für weite Zeiträume
in vielen Kreisen entweder gar keine Daten vorliegen, einfach weil es
keine Infektionen gab, oder die Schätzung auf so wenigen Fällen beruht,
dass sie recht wenig Bedeutung hat. Letzteres würde ein starkes
Blubbersignal liefern, das in Wirklichkeit nur das Rauschen schlechter
Schätzungen beziehungsweise schlecht definierter Verteilungen ist.
Deshalb habe ich die Inzidenz in die Transparenz gesteckt; zwecks
Abstand vom Hintergrund-Weiß fange ich dabei aber gleich bei 20% an,
und weil mir 100 Fälle robust genug erscheinen, setze ich ab einer
14-Tage-Inzidenz von 100 auch 100% Deckung. Wo Daten ganz fehlen,
male ich nur die Umrisse der Kreise.
Was habe ich aus dem Film gelernt? Nun, offen gestanden erheblich
weniger als aus dem Inzidenzfilm im letzten Post. Ich hatte eigentlich
gehofft, dass (mit der derzeitigen Colourmap) ein dramatischer Umschwung
von rötlich nach bläulich stattfindet, wenn Anfang 2021 die Impfungen in
den großen Altenpflegeeinrichtungen anlaufen. Das ist aber allenfalls
dann sichtbar, wenn mensch genau drauf aufpasst. Überhaupt hat mich
überrascht, wie niedrig die Alters-Scores doch meist sind. Hätte ich
vorher nachgedacht, hätten sowohl die Inzidenz-Heatmap des RKI wie auch
einige Prosa zu den Altersverteilungen das allerdings schon stark
nahegelegt, so etwa im letzten Wochenbericht des RKI:
Von allen Todesfällen waren 79.101 (86%) Personen 70 Jahre und älter,
der Altersmedian lag bei 84 Jahren. Im Unterschied dazu beträgt der
Anteil der über 70-Jährigen an der Gesamtzahl der übermittelten
COVID-19-Fälle etwa 13 %.
– Corona war zwar von den Folgen her vor allem ein Problem ziemlich
alter Menschen, getragen haben die Pandemie aber praktisch durchweg die
jüngeren.
Aufschlussreich ist vielleicht, dass die Kreise meist von Blau nach Rot
gehen, Ausbrüche also bei relativ jungen Personen anfangen und sich zu
älteren hinbewegen. Das ist schon beim Heinsberg-Ausbruch zu sehen, der
mit einem Score von 36 anfängt (das hätte ich für einen Kappenabend
nie vorhergesagt) und recht monoton immer weiter steigt.
Bei etwa 55 habe ich ihn aus den Augen verloren. Diese, wenn mensch so
will, Rotverschiebung ist ein recht häufig zu beobachtendes Phänomen in
dem Film. Mein unheimlicher Verdacht ist ja, dass dabei die
outgesourcten Putz- und Pflegekräfte, die im Namen der Kostenersparnis
nicht selten als Kolonne durch mehrere Altenpflegeeinrichtungen
hintereinander gescheucht werden, eine große Rolle gespielt haben.
Recht erwartbar war, dass bei den „jungen“ Kreisen regelmäßig
Unistädte auftauchen, Göttingen z.B. im ansonsten ruhigen Juni 2020,
während gleichzeitig in Gütersloh die Tönnies-Wanderarbeiter deutlich
höhere Alters-Scores haben – beeindruckend, dass diese die Schinderei in
unseren Schlachthöfen in das bei diesem Ausbruch starke A35-A59-bin
durchhalten.
In dieser Ausprägung nicht erwartet hätte ich die grün-rot-Trennung
zwischen West- und Ostdeutschland in der zweiten Welle, besonders
deutlich im Januar 2021. Ein guter Teil davon wird sicher die
Basisdemographie sein, denn arg viele junge Leute, die überhaupt krank
werden könnten, gibt es in weiten Teilen Ostdeutschlands nicht mehr.
Aber so viel anders dürfte das in vielen ländlichen Kreisen
Westdeutschlands auch nicht sein. Hm. Ich brauche gelegentlich nach
Alter und Kreis aufgelöste Demographiedaten für die BRD.
Nehmen wir mal den Landkreis Hof, der im Juni 2021 in den fünf jüngsten
Kreisen mitspielt: da würde ich eigentlich eine recht alte Bevölkerung
erwarten. Der niedrige Score in der Zeit ist also be-stimmt Folge von,
jaklar, den wilden Parties der Jugend, von denen wir schon im Sommer
2020 so viel gehört haben. Naughty kids.
Mit anderen Worten: Ich habe leider keine sehr tiefen Erkenntnisse aus
der Visualisierung gezogen. Wenn das, was da gezeigt ist, nicht
ziemlich ernst wäre, könnte mensch sich immerhin an der
lavalampenähnlichen Erscheinung freuen.
Das Umschreiben des Codes vom vorigen Post war eine interessante
Übung, die insbesondere eine (vor dem Hintergrund der Empfehlung der
Gang of Four, normalerweise eher über Komposition als über Vererbung
nachzudenken) recht natürliche Anwendung von Vererbung mit sich brachte,
nämlich in der Plotter-Klasse. Auch die Parametrisierung dessen,
worüber iteriert wird (_iter_maps, iter_freqs,
iter_age_scores) war, nun, interessant.
Das Programm hat dabei eine (fast) ordentliche
Kommandozeilenschnittstelle bekommen:
$ python3 mkmovie.py --help
usage: mkmovie.py [-h] [-d] [-i N] [-m ISODATE] {inc,age}
Make a movie from RKI data
positional arguments:
{inc,age} select what kind of movie should be made
optional arguments:
-h, --help show this help message and exit
-d, --design_mode just render a single frame from a dict left in a
previous run.
-i N, --interpolate N
interpolate N frames for one day
-m ISODATE, --min-date ISODATE
discard all records earlier than ISODATE
Damit entsteht der Film oben durch:
$ python3 mkmovie.py --min-date=2020-02-20 -i 7 age
Inzidenzen mögen nicht mehr das ideale Mittel sein, um die aktuelle
Corona-Gefährdungslage zu beschreiben, auch wenn es zumindest so lange
kaum ein schnelleres Signal geben wird, wie nicht flächendeckend
PCR auf Abwässer läuft. Aber sie ist bei allen auch hier
angemäkelten Defiziten und Ungenauigkeiten doch kaum zu schlagen, wenn
es um ein nach Zeit und Ort aufgelöstes Bild davon geht, was das Virus
– Verzeihung, die Viren – so getrieben haben.
Und nachdem ich neulich angefangen hatte, mit dem großen
Infektions-Datensatz des RKI zu spielen, ist mir aufgefallen, dass es
ausgehend von dem dort diskutierten Code nicht schwierig sein sollte,
einen Film zu basteln, der die Inzidenzverläufe auf Kreisebene
visualisiert. Nun, das habe ich gemacht:
Nur damit sich niemand wundert, wie Herbst-Zahlen in einen Post vom
August kommen: Ich habe den Film bis November 2021 fortgesetzt und
werde ihn künftig wohl noch ein paar Mal aktualisieren.
Ein paar Dinge, die ich daraus gelernt habe:
Es gab offenbar schon vor Heinsberg einiges an Corona-Rauschen in der
Republik (am Anfang vom Video). Wie viel davon einfach Tippfehler
sind, ist natürlich schwer zu sagen. Aber einiges wird schon real
sein, und dann ist sehr bemerkenswert, dass es in keiner dieser
Fälle zu einem klinisch auffallenden Ausbruch gekommen ist. Das wäre
eine sehr deutliche Illustration der hohen Überdispersion zumindest
des ursprünglichen Virus: fast alle Infizierten steck(t)en [1]
niemanden an, so dass, solange die Ausbrüche klein sind, sie schnell
wieder verschwinden.
Ich hatte ganz vergessen, wie schnell am Anfang der Pandemie die Folgen
des Bierfests in Tirschenreuth die des Kappenabends in Heinsberg
überrundet hatten (nämlich so um den 10.3. rum). Es lohnt sich, im
März 2020 Ostbayern im Blick zu halten.
Die etwas brodelnde Erscheinung des Bildes speziell in ruhigeren
Phasen – wie ein träge kochender Brei vielleicht, bei dem an
mehr oder minder zufälligen Stellen immer mal wieder eine Blase
hochkommt – zeigt wieder, dass sich Corona vor allem in Ausbrüchen
ausbreitet. Das tut es bestimmt auch in weniger ruhigen Phasen, aber
dann sind überall Blasen („sprudelnd kochend“), so dass das nicht mehr
auffällt.
Die großen Ausbrüche des Sommers 2020 (vor allem Gütersloh und
Dingolfing) waren erstaunlich allein stehende Ereignisse.
Wenn mensch bedenkt, dass es ja schon einen Haufen Schlachthöfe und
andere ähnlich furchtbare Betriebe in der BRD gibt, fragt sich
schon, warum es nicht mehr Ausbrüche im Tönnies-Stil gab. Waren die
anderen Läden alle vorsichtiger? Oder hatten die einfach Glück, weil
niemand mit hoher Virusausscheidung in ihre Betriebshallen gekommen
ist? Sind vielleicht Ausbrüche übersehen worden? Rein demographisch
nämlich waren beispielsweise die Tönnies-Leute so jung und fit, dass
nur wenige im Krankenhaus landeten und keineR gestorben ist.
Auch in den zweiten und dritten Wellen blieb erstaunlich viel Struktur
im Infektionsgeschehen – mehr, als ich nach Betrachtung der statischen
RKI-Plots und der relativ parallelen Bundesländer-Inzidenzen erwartet
hätte, vor allem aber entgegen der Einlassung, das Geschehen sei
„diffus“. Angesichts des weiter bestehenden „Brodelns“ würde mich eigentlich
überraschen, wenn sich B.1.1.7 oder die B.1.617.x so viel anders
ausbreiten würden als der ursprüngliche Wildtyp.
Insbesondere gibt es auch in den späteren Wellen Kreise, die kurz
„hochbubbeln“ und dann auch wieder rasch unauffällig werden. Es wäre
bestimmt aufschlussreich, wenn mensch wüsste, warum das mit dem
Rasch-Unauffällig-Werden in den Kreisen in Südsachsen und -thüringen
über lange Zeit nicht passiert ist.
Es war übrigens doch nicht so ganz einfach, diesen Film zu machen, und
zwar vor allem, weil ich eine Weile mit den Polygonen für die
Kreise gerungen habe. Mein erster Plan war, die einfach aus der
Openstreetmap zu ziehen. Ich wollte aber nicht an einem kompletten
OSM-Dump herumoperieren, und so war ich sehr angetan von
osm-boundaries. Mit diesem Dienst ließen sich eigentlich recht
leicht die „administrative boundaries“ von Kreisen (das wäre dort Level
6) in geojson bekommen.
Abgesehen davon aber, dass die interaktive Auswahl gerne mit „cannot
download tree“ scheiterte, mein Webkit lange am Javascript kaute, und
Cloudflare die Downloads regelmäßig zu früh abbrach (die MacherInnen von
osm-boundaries verstehen das selbst nicht so ganz), sind die Label der
Kreise doch sehr verschieden von dem, was das RKI hat: „Solingen
(Klingenstadt)“ auf RKI-Seite war ebenso lästig wie fehlende
Unterscheidung zwischen Stadt- und Landkreisen in den Bezeichnungen der
Openstreetmap (was immerhin durch Betrachtung der Flächen zu umgehen war).
Aber auch, als ich mir die Abbildung zwischen den verschiedenen
Bezeichnern zusammengehackt hatte, blieben einige weiße Flecken, Kreise
also, die ich in der Openstreetmap schlicht nicht finden konnte. An dem
Punkt bin ich zur offiziellen Quelle gegangen, nämlich dem
Bundesamt für Kartographie und Geodäsie, speziell zum
VG2500-Datensatz, der zu meiner großen Erleichterung auch die
Kreis-Identifier des RKI (1001 etwa für Flensburg-Stadt) enthält. Na ja,
abgesehen von Berlin, das das RKI aufteilt, was wiederum etwas Gefummel
zur Wiedervereinigung von Berlin im Code braucht.
Aber leider: Der Kram kommt als Shape, wie das BKG sagt ein
„De-facto-Industriestandard“, mit dem allerdings ich noch nie etwas zu
tun hatte und der als über einige Dateien verteilte Binärsoße daherkommt.
Immerhin: das Debian-paketierte Cartopy kann damit umgehen. Puh.
Nur: frech add_geometries auf die Geometrien loslassen,
die aus dem Reader herausfallen, führt zu einer leeren Karte.
Im Folgenden bin ich etwas untergegangen in all den Referenzsystemen,
mit denen sich die GeographInnen so rumschlagen müssen. Ach, haben wir
es gut in der Astronomie. Ja, klar, auch wir haben einen Haufen
verschiedene Äquatoren und Nullpunkte (z.B. zwei verschiedene Systeme
für galaktische Koordinaten, und haufenweise historische äquatoriale
Systeme, die zudem durch verschiedene Sternkataloge definiert waren):
Aber letztlich sind das im Wesentlichen Drehungen mit winzigen
Knitterungen, und schlimmstenfalls kommen die Dinge halt am falschen
Platz raus, was für meine gegenwärtigen Zwecke völlig wurst gewesen
wäre.
Aber hier: Nichts auf der ganzen Karte. Es braucht beim Plotten
zwingend das richtige Quell-Bezugssystem, hier (wie aus dem .prj des
VG2500 hervorgeht) das EPSG-System Nummer 25832
(Fünfundzwanzigtausenachthundertzweiundreißig! Holy Cow!).
Damit kann Cartopy sogar umgehen, aber es zieht dann bei jedem
Programmlauf die Beschreibung des Systems erneut von einem Onlinedienst,
und das geht in meiner Welt gar nicht. Deshalb habe ich mir geschwind
eine Proj4Projection-Klasse gefummelt, die den String, der von
dem Online-Dienst kommt, händisch in die zugrundeliegende Bibliothek
packt. Warnung: Das ist ohne Sachkenntnis geschrieben; dass ich da die
Gültigkeitsgrenzen völlig fake, ist vermutlich Gift außerhalb dieser
spezifischen Anwendung.
Der Rest des Codes ist harmloses Python, das die Eingabedaten
hinmassiert. Weil die RKI-Daten leider nach Kreis und nicht nach Datum
sortiert sind, muss ich den kompletten Datensatz ins RAM nehmen; auf
nicht völlig antiker Hardware ist das aber kein Drama.
Was für den optischen Eindruck noch ziemlich wichtig ist: Ich
interpoliere linear zwischen den Tagen (die
iter_interpolated-Funktion). Das ist nützlich, weil damit die
Übergänge nicht so hart sind, und auch, damit der Film nicht nur 25
Sekunden (also rund 600 Frames) lang ist, sondern etwas wie zwei Minuten
läuft.
Wers nachbauen will oder z.B. Altersgruppen-spezifische Filme machen
will oder welche mit dem Median des Alters – das würde der Datensatz
durchaus hergeben – oder welche, die nicht alles über 350 saturiert
darstellen oder so etwas, braucht mkmovie.py und corona.py. Die
Quelldaten werden in einem in corona.py definierten externen Verzeichnis
erwartet (DATA_DIR); welche, und woher die kommen, steht am Kopf von
mkmovie.py.
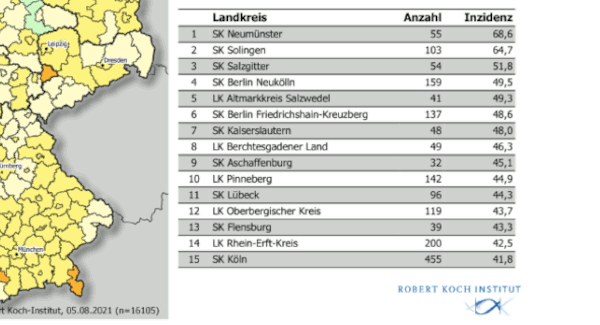
Anlass meiner Paranoia: Im RKI-Bericht von heute drängeln sich
verdächtig viele Kreise gerade unter der 50er-Inzidenz.
Mein Abgesang auf die RKI-Berichte von neulich war wie erwartet etwas
voreilig: Immer noch studiere ich werktäglich das Corona-Bulletin des
RKI. Es passiert ja auch wieder viel in letzter Zeit. Recht
schnell schossen die ersten Landkreise im Juli über die 50er-Schwelle,
während die breite Mehrheit der Kreise noch weit von ihr entfernt war.
Das ist, klar, auch so zu erwarten, wenn die „Überdispersion“ (find ich
ja ein komisches Wort für „die Verteilung der Zahl der von einem_r
Infizierten Angesteckten hat einen langen Schwanz nach oben hin“, aber
na ja) noch irgendwie so ist wie vor einem Jahr, als, wie im inzwischen
klassischen Science-Artikel von Laxminarayan et al (DOI
10.1126/science.abd7672) auf der Grundlage von Daten aus Indien
berichtet wurde, 5% der Infizierten 80% der Ansteckungen verursachten
(und umgekehrt 80% der Infizierten gar niemanden ansteckten): SARS-2
verbreitete sich zumindest in den Prä-Alpha- und -Delta-Zeiten in
Ausbrüchen.
Nachdem aber die ersten Landkreisen die 50 gerissen hatten, tat sich für
eine ganze Weile im Bereich hoher Inzidenzen nicht viel; auch heute sind
nur drei Landkreise über der 50er-Inzidenz, während sich knapp darunter
doch ziemlich viele zu drängen scheinen.
Und da hat sich ein Verdacht in mir gerührt: Was, wenn die
Gesundheitsämter sich mit Händen und Füßen wehren würden, über die
vielerorts immer noch „maßnahmenbewehrte“ 50er-Schwelle zu gehen und
ihre Meldepraktiken dazu ein wenig… optimieren würden? Wäre das so,
würde mensch in einem Histogramm der Inzidenzen (ein
Häufigkeit-von-Frequenzen-Diagram; ich kann die nicht erwähnen ohne
einen Hinweis auf Zipfs Gesetz) eine recht deutliche Stufe bei der 50
erwarten.
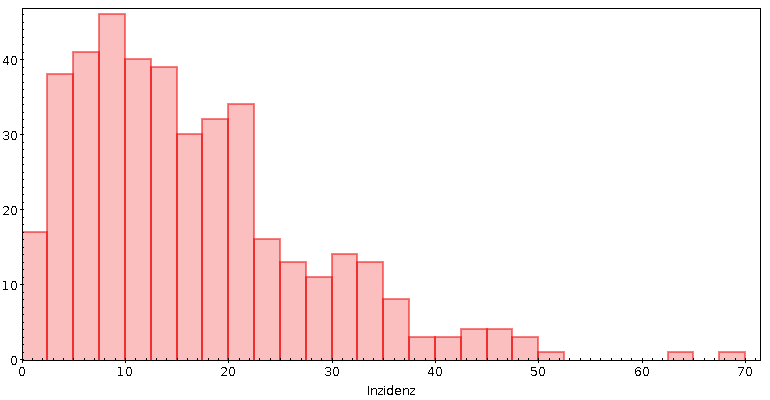
Gibt es die? Nun, das war meine Gelegenheit, endlich mal mit den
Meldedaten zu spielen, die das RKI bereitstellt – zwar leider auf
github statt auf eigenen Servern, so dass ich mit meinen Daten statt mit
meinen Steuern bezahle (letzteres wäre mir deutlich lieber), aber das
ist Jammern auf hohem Niveau. Lasst euch übrigens nicht einfallen, das
ganze Repo zu klonen: Das sind ausgecheckt wegen eines gigantischen
Archivs krasse 24 GB, und was ihr tatsächlich braucht, sind nur die
aktuellen Zahlen (Vorsicht: das sind auch schon rund 100 MB, weil das
quasi die ganze deutsche Coronageschichte ist) und der
Landkreisschlüssel (vgl. zu dem Update unten).
Auch mit diesen Dateien muss mensch erstmal verstehen, wie aus deren
Zeilen die Inzidenzen werden, denn es ist nicht etwa so, dass jede Zeile
einer Erkrankung entspricht: Nein, manche berichten mehrere Fälle, es
wird nach schon gemeldeten und ganz neuen Fällen unterschieden, und
eventuell gibts auch noch Korrekturzeilen. Dazu findet ein
in-band-signalling zu Gestorbenen und Genesenen statt. Lest das README
aufmerksam, sonst verschwendet ihr nur (wie ich) eure Zeit:
EpidemiologInnen denken ganz offenbar etwas anders als AstronomInnen.
Das Ergebnis ist jedenfalls das hier:
Ich muss also meinen Hut essen: Wenn da irgendwo
Hemmschwellen sein sollten, dann eher knapp unter 40, und das ist,
soweit ich weiß, in keiner Corona-Verordnung relevant. Na ja, und der
scharfe Abfall knapp unter 25 könnte zu denken geben. Aber warum würde
jemand bei der 25 das Datenfrisieren anfangen? Der Farbe im RKI-Bericht
wegen? Nee, glaub ich erstmal nicht.
Wenn ihr selbst mit den RKI-Daten spielen wollt, kann euch das Folgende
vielleicht etwas Fummeln ersparen – hier ist nämlich mein
Aggregationsprogramm. Ich werdet die Dateipfade anpassen müssen, aber
dann könnt ihr damit eure eigenen Inzidenzen ausrechnen, ggf. auch nach
Altersgruppen, Geschlechtern und was immer. In dem großen CSV des RKI
liegt in der Tat auch die Heatmap, die jetzt immer im Donnerstagsbericht
ist. Reizvoll fände ich auch, das gelegentlich zu verfilmen…
Hier jedenfalls der Code (keine Abhängigkeiten außer einem nicht-antiken
Python). So, wie das geschrieben ist, bekommt ihr eine Datei
siebentage.csv mit Landkreisnamen vs. Inzidenzen; die entsprechen
zwar nicht genau dem, was im RKI-Bericht steht, die Abweichungen sind
aber konsistent mit dem, was mensch von lebenden Daten erwartet:
# (RKI-Daten zu aktuellen 7-Tage-Meldeinzidenzen: Verteilt unter CC-0)
import csv
import datetime
import sys
LKR_SRC = "/media/incoming/2020-06-30_Deutschland_Landkreise_GeoDemo.csv"
INF_SRC = "/media/incoming/Aktuell_Deutschland_SarsCov2_Infektionen.csv"
LANDKREIS = 0
MELDEDATUM = 3
REFDATUM = 4
NEUER_FALL = 6
ANZAHL_FALL = 9
def getcounts(f, n_days=7):
counts = {}
collect_start = (datetime.date.today()-datetime.timedelta(days=n_days)
).isoformat()
sys.stderr.write(f"Collecting from {collect_start} on.\n")
row_iter = csv.reader(f)
# skip the header
next(row_iter)
for row in row_iter:
if row[MELDEDATUM]>=collect_start:
key = int(row[LANDKREIS])
kind = row[NEUER_FALL]
if kind!="-1":
counts[key] = counts.get(key, 0)+int(row[ANZAHL_FALL])
return counts
def get_lkr_meta():
lkr_meta = {}
with open(LKR_SRC, "r", encoding="utf-8") as f:
for row in csv.DictReader(f):
row["IdLandkreis"] = int(row["IdLandkreis"])
row["EW_insgesamt"] = float(row["EW_insgesamt"])
lkr_meta[row["IdLandkreis"]] = row
return lkr_meta
def main():
lkr_meta = get_lkr_meta()
with open(INF_SRC, "r", encoding="utf-8") as f:
counts = getcounts(f)
with open("siebentage.csv", "w", encoding="utf-8") as f:
f.write("Lkr, Inzidenz\n")
w = csv.writer(f)
for lkr in lkr_meta.values():
w.writerow([lkr["Gemeindename"],
1e5*counts.get(lkr["IdLandkreis"], 0)/lkr["EW_insgesamt"]])
if __name__=="__main__":
main()
Nachtrag (2021-08-13)
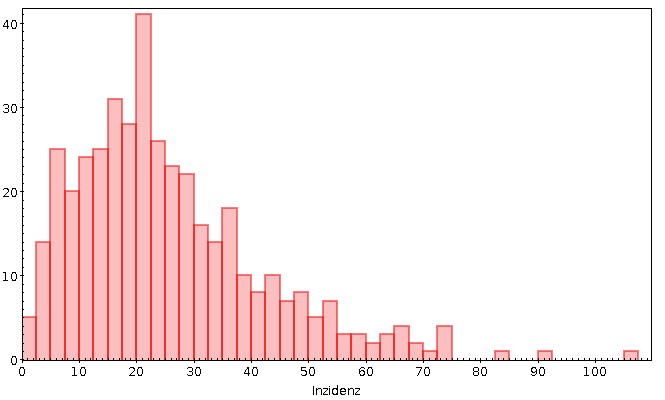
Eine Woche später ist der Damm definitiv gebrochen. Von drei
Landkreisen über dem 50er-Limit sind wir laut aktuellem RKI-Bericht
jetzt bei 39, wobei allein seit gestern 10 dazukamen. An die aktuelle
Verteilung würde ich gerne mal eine Lognormalverteilung fitten:
Nicht, dass ich eine gute Interpretation hätte, wenn das lognormal wäre.
Aber trotzdem.
Nachtrag (2021-09-08)
Das RKI hat die Landkreis-Daten
(2020-06-30_Deutschland_Landkreise_GeoDemo.csv) aus ihrem
Github-Repo entfernt (commit cc99981f, „da diese nicht mehr aktuell
sind“; der letzte commit, der sie noch hat, ist 0bd2cc53). Die aus
der History rausklauben würde verlangen, das ganze Riesending zu
clonen, und das wollt ihr nicht. Deshalb verteile ich unter dem Link
oben die Datei unter CC-BY 4.0 International, mit Namensnennung… nun,
Destatis wahrscheinlich, oder halt RKI; die Lizenzerklärung auf dem
Commit ist nicht ganz eindeutig. Als Quelle der Geodaten war vor der
Löschung
https://www.destatis.de/DE/Themen/Laender-Regionen/Regionales/Gemeindeverzeichnis/Administrativ/Archiv/
angegeben, aber da finde ich das nicht.
Morgen werden zwei Wochen seit meiner zweiten Corona-Impfung vergangen
sein. Damit wird die Impfpassfrage für mich relevant: Mit so einem Ding
könnte ich wieder in die Mensa gehen!
Allerdings habe ich, soweit ich das sehe, keinen Zugang zur
offiziellen Covpass-App, weil ich mich von Apples Appstore und Googles
Playstore fernhalte und eigentlich auch die Toolchains der beiden nicht
auf meinem Rechner haben will. Immerhin gibt es (es lebe der
Datenschutz-Aktivismus, der für offene Entwicklung von dem Kram gesorgt
hat) die Quellen der Apps (wenn auch leider auf github). Wie
kompliziert kann es schon sein, das ohne den ganzen proprietären Zauber
nachzubauen?
Stellt sich raus: schon etwas, aber es ist ein wenig wie eine
Kurzgeschichte von H.P. Lovecraft: Die Story entwickelt sich wie
beim Schälen einer Zwiebel. Schale um Schale zeigt sich, dass die
Wahrheit immer noch tiefer liegt.
Bei Lovecraft sind nach dem Abpulen der letzten Schale meist alle
ProtagonistInnen tot oder wahnsinnig. Im Fall der Covpass-App hingegen
ist der Kram sogar dokumentiert: So finden sich die halbwegs
lesbare Dokumentation des Datenstroms im QR-Code und das
JSON-Schema – leider schon wieder auf github.
Schale 1: QR-Code scannen
Ich dachte mir, zum Nachbauen der Covpass-App sollte ich erstmal ihre
Eingabe verstehen, also die Daten aus den beiden Impfzertifikaten lesbar
darstellen. Der erste Schritt dazu ist etwas, das QR-Codes lesen kann.
Ich hatte anderweitig schon mit zbar gespielt, für das es das
Debian-Paket python3-zbar gibt. Damit (und mit der unverwüstlichen
Python Imaging Library aus python3-pillow) geht das so, wenn das Foto
mit dem Zertifikat in der Datei foto.jpeg liegt:
def get_single_qr_payload(img):
img = img.convert("L")
scanner = zbar.ImageScanner()
scanner.parse_config('enable')
image = zbar.Image(img.size[0], img.size[1], 'Y800', data=img.tobytes())
if not scanner.scan(image):
raise ValueError("No QR code found")
decoded = list(image)
if len(decoded)>1:
raise ValueError("Multiple QR codes found")
return decoded[0].data
encoded_cert = get_single_qr_payload(Image.open("foto.jpeg"))
Im Groben wandele ich in der Funktion das Bild (das wahrscheinlich in
Farbe sein wird) in Graustufen, denn nur damit kommt zbar zurecht. Dann baue
ich eine Scanner-Instanz, also das Ding, das nachher in Bildern nach
QR-Codes sucht. Die API hier ist nicht besonders pythonesk, und ich habe
längst vergessen, was parse_config('enable') eigentlich tut – egal,
das ist gut abgehangene Software mit einem C-Kern, da motze ich nicht,
noch nicht mal über diesen fourcc-Unsinn, mit dem vor allem im Umfeld
von MPEG allerlei Medienformate bezeichnet werden; bei der Konstruktion
des zbar.Image heißt „8 bit-Graustufen“ drum "Y800". Na ja.
Der Rest der Funktion ist dann nur etwas Robustheit und wirft
ValueErrors, wenn im Foto nicht genau ein QR-Code gefunden wurde. Auch
hier ist die zbar-API vielleicht nicht ganz preiswürdig schön, aber nach
dem Scan kann mensch über zbar.Image iterieren, was die verschiedenen
gefundenen Barcodes zurückgibt, zusammen mit (aus meiner Sicht eher
knappen) Metadaten. Das .data-Attribut ist der gelesene Kram, hier
als richtiger String (im Gegensatz zu bytes, was ich hier nach der
python3-Migration eher erwartet hätte).
Schale 2: base45-Kodierung
Das Ergebnis sieht nach üblichem in ASCII übersetzten Binärkram aus.
Bei mir fängt der etwa (ich habe etwas manipuliert, das dürfte so also
nicht dekodieren) so an: HC1:6B-ORN*TS0BI$ZDFRH%. Insgesamt sind
das fast 600 Zeichen.
Als ich im Wikipedia-Artikel zum Digitalen Impfnachweis gelesen habe,
das seien base45-kodierte Daten, habe ich erst an einen Tippfehler
gedacht und es mit base85 versucht, das es in Pythons base64-Modul
gibt. Aber nein, weit gefehlt, das wird nichts. War eigentlich klar:
die Wahrscheinlichkeit, dass was halbwegs Zufälliges base85-kodiert
keine Kleinbuchstaben enthält, ist echt überschaubar. Und base45 gibts
wirklich, seit erstem Juli in einem neuen RFC-Entwurf, der sich
explizit auf QR-Codes bezieht. Hintergrund ist, dass der QR-Standard
eine Kodierungsform (0010, alphanumeric mode)
vorsieht, die immer zwei Zeichen in 11 bit packt und
dafür nur (lateinische) Großbuchstaben, Ziffern und ein paar
Sonderzeichen kann. Extra dafür ist base45 erfunden worden. Fragt mich
bloß nicht, warum die Leute nicht einfach binäre QR-Codes verwenden.
Es gibt bereits ein Python-Modul für base45, aber das ist noch nicht in
Debian bullseye, und so habe ich mir den Spaß gemacht, selbst einen
Dekodierer zu schreiben. Technisch baue ich das als aufrufbares (also
mit einer __call__-Methode) Objekt, weil ich die nötigen Tabellen
aus dem globalen Namensraum des Skripts draußenhalten wollte. Das ist
natürlich ein Problem, das verschwindet, wenn sowas korrekt in ein eigenes
Modul geht.
Aber so gehts eben auch:
class _B45Decoder:
chars = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ $%*+-./:"
code_for_char = dict((c, i) for i, c in enumerate(chars))
sig_map = [1, 45, 45*45]
def __call__(self, str):
raw_bytes = [self.code_for_char[s] for s in str]
cooked_bytes = []
for offset in range(0, len(raw_bytes), 3):
next_raw = raw_bytes[offset:offset+3]
next_bytes = sum(w*v for w,v in
zip(self.sig_map, next_raw))
if len(next_raw)>2:
cooked_bytes.append(next_bytes//256)
cooked_bytes.append(next_bytes%256)
return bytes(cooked_bytes)
b45decode = _B45Decoder()
Die b45decode-Funktion ist, wenn mensch so will, ein
Singleton-Objekt der _B45Decoder-Klasse (so hätten das jedenfalls
die IBMlerInnen der CovPass-App beschrieben, vgl. unten). Ansonsten
bildet das den Grundgedanken von base45 ziemlich direkt ab: Immer drei
Bytes werden zur Basis 45 interpretiert, wobei die Wertigkeit der
verschiedenen Zeichen im Dictionary code_for_char liegt. Die
resultierende Zahl lässt sich in zwei dekodierte Bytes aufteilen. Nur
am Ende vom Bytestrom muss mensch aufpassen: Wenn die dekodierte Länge
ungerade ist, stehen kodiert nur zwei Byte.
Und ja: vielleicht wärs hübscher mit dem grouper-Rezept aus der
itertools-Doku, aber die next_raw-Zuweisung schien mir klar genug.
Schale 3: zlib
Ein b45decode(encoded_cert) gibt erwartungsgemäß wilden Binärkram
aus, etwas wie b'x\x9c\xbb\xd4\xe2\xbc\x90Qm!… Das sind,
ganz wie die Wikipedia versprochen hat, zlib-komprimierte Daten. Ein
zlib.decompress wirkt und führt auf etwas, in dem zum ersten Mal
irgendetwas zu erkennen ist; neben viel Binärkram findet sich etwa:
An dieser Stelle bin ich auf mir unbekanntes Terrain vorgestoßen:
CBOR, die Concise Binary Object Representation (Nerd-Humor: erfunden hat
das Carsten Bormann, weshalb ich auch sicher bin, dass das Akronym vor
der ausgeschriebenen Form kam) alias RFC 7049. Gedacht ist das als
so eine Art binäres JSON; wo es auf die Größe so ankommt wie bei
QR-Codes, habe ich schon Verständnis für diese Sorte Sparsamkeit.
Dennoch: Sind Protocol Buffers eigentlich tot?
Praktischerweise gibt es in bullseye das Paket python3-cbor2.
Munter habe ich cbor2.loads(raw_payload) geschrieben und war doch
etwas enttäuscht, als ich etwas wie:
zurückbekommen habe. Das ist deutlich mehr viel Binärrauschen als ich
erhofft hatte. Aber richtig, das Zeug sollte ja signiert sein, damit
die Leute sich ihre Impf- und Testzertifikate nicht einfach selbst
schreiben. Die hier genutzte Norm heißt COSE (nämlich CBOR Object
Signing and Encryption, RFC 8152 aus dem Jahr 2017). Ich habe das
nicht wirklich gelesen, aber Abschnitt 2 verrät gleich mal, dass, wer an
einer Signaturprüfung nicht interessiert ist (und das bin ich nicht,
solange ich nicht vermuten muss, dass meine Apotheke mich betrogen hat),
einfach nur aufs dritte Arrayelement schauen muss. Befriedigenderweise
ist das auch das längste Element.
Ein wenig neugierig war ich aber schon, was da noch so drinsteht. Die
18 aus dem CBORTag heißt nach Abschnitt 4.2, dass das eine Nachricht mit nur
einer Unterschrift ist, und der letzte Binärkram ist eben diese eine
Unterschrift. Das erste Array-Element sind Header, die mit
unterschrieben werden, wieder CBOR-kodiert. Dekodiert ist das {1:
-7}, und Überfliegen der COSE-Spezifikation (Tabellen 2 und 5) schlägt
vor, dass das heißt: der Kram ist per ECDSA mit einem SHA-256-Hash
unterschrieben.
Tabelle 2 von COSE erklärt auch das nächste Element, die Header,
die nicht unterschrieben werden (und über die mensch also Kram in die
Nachrichten einfummeln könnte). Das sieht auch erstmal binär aus, ist
aber ein „entpacktes“ Dictionary: In meiner Nachricht steht da nur ein
Header 4, was der „Key Identifier“ ist. Der Binärkram ist schlicht eine
64-bit-Zahl, die angibt, mit welchem Schlüssel die Unterschrift gemacht
wurde (bei PGP wären das die letzten 8 byte des Fingerabdrucks, viel
anders wird das bei COSE auch nicht sein).
Schale 5: CBOR lesbar machen
Zurück zu den Zwiebelschalen. Wenn also die Nutzdaten im dritten
Element des Array von oben sind, sage ich:
– das ist ziemlich offensichtlich die Datenstruktur, die der Zauber
liefern sollte. Nur sind die Schlüssel wirklich unklar. v könnte wohl
„Vaccination“ sein, is der Issuer, also der Herausgeber des
Impfpasses; die Werte von 4 und 6 sehen verdächtig nach Unix-Timestamps
in der nächsten Zeit aus (ja, es sind schon sowas wie 1,6 Milliarden
Sekunden vergangen seit dem 1.1.1970).
Aber Raten ist doof, wenn es Doku gibt. Wie komme ich also zu …
Keine Zikaden in Weinheim: das Eichhörnchen im dortigen Arboretum
konnte noch munter turnen.
Wieder mal eine Tier-Geschichte aus Forschung aktuell am
Deutschlandfunk: In der Sendung vom 25.5. gab es ein Interview mit
Zoe Getman-Pickering, die derzeit eine Massenvermehrung von Zikaden
an der US-Ostküste beobachtet. Im Gegensatz zu so mancher
Heuschreckenplage kam die nicht unerwartet, denn ziemlich verlässlich
alle 17 Jahre schlüpfen erstaunliche Mengen dieser Insekten und
verwandeln das Land in ein
All-You-Can-Eat-Buffet. Es gibt schon Berichte von Eichhörnchen und
Vögeln, die so fett sind, dass sie nicht mehr richtig laufen können.
Die sitzen dann einfach nur herum und fressen eine Zikade nach der
anderen.
Es war dieses Bild von pandaähnlich herumhockenden Eichhörnchen, die
Zikaden in sich reinstopfen wie einE Couch Potato Kartoffelchips, das
meine Fantasie angeregt hat.
Gut: Gereizt hat mich auch die Frage, wo auf der Fiesheitssakala ich
eigentlich einen intervenierenden Teil der Untersuchung ansiedeln würde,
der im Inverview angesprochen wird: Um
herauszufinden [ob die Vögel noch Raupen fressen, wenn sie Zikaden in
beliebigen Mengen haben können], haben wir auch künstliche Raupen aus
einem weichen Kunststoff. Die setzen wir auf die Bäume. Und wenn sich
dann Vögel für die künstlichen Raupen interessieren, dann picken sie
danach
und sind bestimmt sehr enttäuscht, wenn sie statt saftiger Raupen
nur ekliges Plastik schmecken. Na ja: verglichen mit den abstürzenden
Fledermäuse von neulich ist das sicher nochmal eine Stufe harmloser.
Balsam für die Ethikkommission, denke ich. Das Ergebnis übrigens: Ja,
die Zikadenschwemme könnte durchaus eine Raupenplage nach sich ziehen.
Die Geschichte hat ein Zuckerl für Mathe-Nerds, denn es ist ja
erstmal etwas seltsam, dass sich die Zikaden ausgerechnet alle 17 Jahre
verabreden zu ihren Reproduktionsorgien. Warum 17? Bis zu diesem
Interview war ich überzeugt, es sei in ÖkologInnenkreisen Konsens, das
sei, um synchronen Massenvermehrungen von Fressfeinden auszuweichen,
doch Getman-Pickering hat mich da eines Besseren belehrt:
Aber es gibt auch Theorien, nach denen es nichts mit den Fressfeinden
zu tun hat. Sondern eher mit anderen Zikaden. Der Vorteil wäre dann,
dass die Primzahlen verhindern, dass unterschiedliche Zikaden zur
gleichen Zeit auftreten, was dann schlecht für die Zikaden sein
könnte. Und dann gibt es auch noch einige Leute, die es einfach nur
für einen Zufall halten.
Das mit dem Zufall fände ich überzeugend, wenn bei entsprechenden Zyklen
in nennenswerter Zahl auch nichtprime Perioden vorkämen. Und das mag
durchaus sein. Zum Maikäfer zum Beispiel schreibt die Wikipedia:
„Maikäfer haben eine Zykluszeit von drei bis fünf, meist vier Jahren.“
Aua. Vier Jahre würden mir eine beliebig schlechte Zykluszeit
erscheinen, denn da würde ich rein instinktiv Resonanzen mit allem und
jedem erwarten. Beim Versuch, diesen Instinkt zu quantifizien, bin ich
auf etwas gestoßen, das, würde ich noch Programmierkurse geben, meine
Studis als Übungsaufgabe abbekommen würden.
Die Fragestellung ist ganz grob: Wenn alle n Jahre besonders viele
Fressfeinde auftreten und alle m Jahre besonders viele Beutetiere, wie
oft werden sich die Massenauftreten überschneiden und so den
(vermutlichen) Zweck der Zyklen, dem Ausweichen massenhafter
Fressfeinde, zunichte machen? Ein gutes Maß dafür ist: Haben die beiden
Zyklen gemeinsame Teiler? Wenn ja, gibt es in relativ kurzen
Intervallen Jahre, in denen sich sowohl Fressfeinde als auch Beutetiere
massenhaft vermehren. Haben, sagen wir, die Eichhörnchen alle 10 Jahre
und die Zikaden alle 15 Jahre Massenvermehrungen, würden die
Eichhärnchen alle drei Massenvermehrungen einen gut gedeckten Tisch und
die Zikaden jedes zweite Mal mit großen Eichhörnchenmengen zu kämpfen
haben.
Formaler ist das Problem also: berechne für jede Zahl von 2 bis N die
Zahl der Zahlen aus dieser Menge, mit denen sie gemeinsame Teiler hat.
Das Ergebnis:
Mithin: wenn ihr Zikaden seid, verabredet euch besser nicht alle sechs,
zwölf oder achtzehn Jahre. Die vier Jahre der Maikäfer hingegen sind
nicht so viel schlechter als drei oder fünf Jahre wie mir mein Instinkt
suggeriert hat.
Ob die Verteilung von Zyklen von Massenvermehrungen wohl irgendeine
Ähnlichkeit mit dieser Grafik hat? Das hat bestimmt schon mal wer
geprüft – wenn es so wäre, wäre zumindest die These vom reinen Zufall in
Schwierigkeiten.
Den Kern des Programms, das das ausrechnet, finde ich ganz hübsch:
def get_divisors(n):
return {d for d in range(2, n//2+1) if not n%d} | {n}
def get_n_resonances(max_period):
candidates = list(range(2, max_period+1))
divisors = dict((n, get_divisors(n)) for n in candidates)
return candidates, [
sum(1 for others in divisors.values()
if divisors[period] & others)
for period in candidates]
get_divisors ist dabei eine set comprehension, eine relativ neue
Einrichtung von Python entlang der altbekannten list comprehension:
„Berechne die Menge aller Zahlen zwischen 2 und N/2, die N ohne Rest
teilen – und vereinige das dann mit der Menge, in der nur N ist, denn
N teilt N trivial. Die eins als Teiler lasse ich hier raus, denn
die steht ohnehin in jeder solchen Menge, weshalb sie die Balken in der
Grafik oben nur um jeweils eins nach oben drücken würde – und sie würde,
weit schlimmer, die elegante Bedingung divisors[period] & others
weiter unten kaputt machen. Wie es ist, gefällt mir sehr gut, wie
direkt sich die mathematische Formulierung hier in Code abbildet.
Die zweite Funktion, get_n_resonances (vielleicht nicht der beste
Name; sich hier einen besseren auszudenken wäre auch eine wertvolle
Übungsaufgabe) berechnet zunächt eine Abbildung (divisors) der
Zahlen von 2 bis N (candidates) zu den Mengen der Teiler, und dann
für jeden Kandidaten die Zahl dieser Mengen, die gemeinsame Elemente mit
der eigenen Teilermenge haben. Das macht eine vielleicht etwas dicht
geratene generator expression. Generator expressions funktionieren auch
wie list comprehensions, nur, dass nicht wirklich eine Liste erzeugt
wird, sondern ein Iterator. Hier spuckt der Iterator Einsen aus, wenn
die berechneten Teilermengen (divisors.values()) gemeinsame Elemente
haben mit den Teilern der gerade betrachteten Menge
(divisors[period]). Die Summe dieser Einsen ist gerade die gesuchte
Zahl der Zahlen mit gemeinsamen Teilern.
Das Ergebnis ist übrigens ökologisch bemerkenswert, weil kleine
Primzahlen (3, 5 und 7) „schlechter“ sind als größere (11, 13 und 17).
Das liegt daran, dass bei einem, sagen wir, dreijährigen Zyklus dann
eben doch Resonanzen auftauchen, nämlich mit Fressfeindzyklen, die
Vielfache von drei sind. Dass 11 hier so gut aussieht, folgt natürlich
nur aus meiner Wahl von 20 Jahren als längsten vertretbaren Zyklus. Ganz
künstlich ist diese Wahl allerdings nicht, denn ich würde erwarten, dass
allzu lange Zyklen evolutionär auch wieder ungünstig sind, einerseits,
weil dann Anpassungen auf sich ändernde Umweltbedingungen zu
langsam stattfinden, andererseits, weil so lange Entwicklungszeiten rein
biologisch schwierig zu realisieren sein könnten.
Für richtig langlebige Organismen – Bäume zum Beispiel – könnte diese
Überlegung durchaus anders ausgehen. Und das mag eine Spur sein
im Hinblick auf die längeren Zyklen im Maikäfer-Artikel der
Wikipedia:
Diesem Zyklus ist ein über 30- bis 45-jähriger Rhythmus überlagert.
Die Gründe hierfür sind nicht im Detail bekannt.
Nur: 30 und 45 sehen aus der Resonanz-Betrachtung jetzt so richtig
schlecht aus…
„Jetzt ist aber wirklich höchste Zeit, dass Corona endlich mal weggeht“
ist inzwischen ein universelles Sentiment, und auch mich lockt
gelegentlich die autoritäre Versuchung, einen „harten Lockdown“ zu
wünschen, damit das Ding weggeht (was es natürlich nicht täte). Der
Hass auf SARS-2 steigt, und damit womöglich auf Viren allgemein.
In der Tat scheinen Viren erstmal richtig doof, eklig und widerwärtig.
Wie scheiße ist das eigentlich, sich von den Zellen vertrauensvoll
aufnehmen zu lassen und dann den Laden zu übernehmen mit dem
einzigen Ziel, neues Virus zu machen? Und dann die Ähnlichkeit von z.B.
der T2-Bakteriophage mit Invasoren vom Mars...
Andererseits bin ich überzeugt, dass eine gewisse Anfälligkeit gegen
Viren wahrscheinlich ein evolutionärer Vorteil ist. Da gibts bestimmt
jede Menge echte Wissenschaft dazu, aber ich denke, eine einfache
Intiution geht auch ohne: Praktisch alle Viren nämlich wirken nur auf
kurze Distanz in Zeit und Raum (verglichen etwa mit Pflanzenpollen, aber
sogar mit vielen Bakterien), werden also im Wesentlichen bei Begegnungen
übertragen. Da die Wahrscheinlichkeit von Begegnungen mit dem Quadrat
der Bevölkerungsdichte geht, sollten Viren explodierende Populationen
„weicher“ begrenzen als leergefressene Ressourcen und so wahrscheinlich
katastrophalen Aussterbeereignissen vorbeugen.
Vorneweg: Ja, das klingt alles erstmal wild nach Thomas Malthus.
Dessen Rechtfertigung massenhaften Sterbenlassens ist natürlich
unakzeptabel (ebenso allerdings wie das fortgesetzte Weggucken von den
Meadows-Prognosen, die in der Regel auch katastrophale Zusammenbrüche
erwarten lassen).
Dies aber nicht, weil falsch wäre, dass in endlichen Systemen der
Ressourcengebrauch nicht endlos steigen kann; das ist nahe an einer
Tautologie. Nein, Malthus' Fehler ist der der Soziobiologie, nämlich
menschliche Gesellschaft und menschliches Verhalten an Funktionsweisen
der Natur auszurichten. Wer das will, wird recht notwendig zum
Schlächter, während umgekehrt die Geschichte der letzten 100 Jahre
überdeutlich zeigt, wie (sagen wir) Wachstumszwänge diverser Art durch
mehr Bildung, mehr Gleichheit und vor allem durch reproduktive
Selbstbestimmung von Frauen ganz ohne Blutbad und unter deutlicher
Hebung der generellen Wohlfahrt zu beseitigen sind.
Bei Kaninchen ist das aber, da muss ich mich leider etwas als Speziezist
outen, anders. Und daher habe ich mir Modellkaninchen für ein weiteres
meiner Computerexperimente herausgesucht, ganz analog zu den Schurken
und Engeln.
Die Fragestellung ist: Werden Ausschläge in Populationen wirklich
weniger wild, wenn Viren (also irgendwas, das Individuen nach
Begegnungen mit einer gewissen Wahrscheinlichkeit umbringt) im Spiel
sind?
Um das zu untersuchen, baue ich mir eine Spielwelt (wer mag, kann auch
„modifiziertes Lotka-Volterra-Modell“ dazu sagen) wie folgt:
Es gibt 1000 Felder, auf denen Gras wachsen kann oder nicht.
In der Welt leben Kaninchen, die pro Periode ein Grasfeld leerfressen
müssen, damit sie glücklich sind.
Haben Kaninchen mehr Gras als sie brauchen, vermehren sie sich, und
zwar um so mehr, je mehr Extrafutter sie haben (so machen das
zumindest Rehe).
Haben Kaninchen zu wenig Gras, sterben ein paar.
In jeder Periode verdoppelt sich die Zahl der Grasfelder (sagen wir: durch
Aussaat), bis alle 1000 Felder voll sind.
In Code sieht die Berechnung der Vermehrungsrate der Kaninchen so aus:
Wer den Verlauf der Vermehrungsrate mit dem Gras/Kaninchenverhältnis
γ auf der Abszisse sehen will:
Um dieses Modell zu rechnen, habe ich ein kleines Python-Programm
geschrieben, lv.py, das, mit anfänglichen Zahlen von Gras und
Kaninchen aufgerufen, den Verlauf der jeweiligen Populationen im Modell
ausgibt (nachdem es die Anfangsbedingungen etwas rausevolvieren hat
lassen).
Wie bei dieser Sorte von Modell zu erwarten, schwanken die Populationen
ziemlich (außer im Fixpunkt Kaninchen=Gras). So sieht das z.B. für
python3 lv.py 400 410 (also: anfänglich ziemlich nah am
Gleichgewicht) aus:
Das sieht nicht viel anders aus, wenn ich mit einem Kaninchen-Überschuss
anfange (python3 lv.py 400 800):
oder mit einem Gras-Paradies (python3 lv.py 800 150):
Aus Modellsicht ist das schon mal fein: Recht unabhängig von den
Anfangsbedingungen (solange sie im Rahmen bleiben) kommen zwar
verschiedene, aber qualitativ doch recht ähnliche Dinge raus: die
Kaninchenpopulationen liegen so zwischen 250 und 600 – im anfänglichen
Gras-Paradies auch mal etwas weiter auseinander – und schwanken wild von
Schritt zu Schritt.
Jetzt baue ich einen Virus dazu. Im lv.py geht das durch Erben vom
LV-Modell, was auf die LVWithVirus-Klasse führt. Diese hat einen
zusätzlichen Parameter, deadliness, der grob sagt, wie
wahrscheinlich es ist, dass ein Kaninchen nach einer Begegnung mit einem
anderen Kaninchen stirbt. Die Mathematik in der propagate-Methode,
würde etwa einem Bau entsprechen, in dem sich alle Kaninchen ein Mal
pro Periode sehen. Das ist jetzt sicher kein gutes Modell für
irgendwas, aber es würde mich sehr überraschen, wenn die Details der
Krankheitsmodellierung viel an den qualitativen Ergebnissen ändern
würden. Wichtig dürfte nur sein, dass die Todesrate irgendwie
überlinear mit der Population geht.
lv.py lässt das Modell mit Virus laufen, wenn es ein drittes
Argument, also die Tödlichkeit, bekommt. Allzu tödliche Viren löschen die
Population aus (python3 lv.py 800 150 0.05):
Zu harmlose Viren ändern das Verhalten nicht nennenswert
(python3 lv.py 800 150 1e-6):
Interessant wird es dazwischen, zum Beispiel python3 lv.py 800 150
2.1e-4 (also: rund jede fünftausendste Begegnung bringt ein Kaninchen um):
– wer an die Beschriftung der Ordinate schaut, wird feststellen, dass
die Schwankungen tatsächlich (relativ) kleiner geworden sind.
Das Virus wirkt offenbar wirklich regularisierend.
Wir befinden uns aber im Traditionsgebiet der Chaostheorie, und so
überrascht nicht, dass es Bereiche der Tödlichkeit gibt, in denen
plötzlich eine starke Abhängigkeit von den Anfangsbedingungen entsteht
und sich die Verhältnisse weit in die Entwicklung rein nochmal
grundsätzlich ändern können („nicht-ergodisch“). So etwa python3
lv.py 802 300 0.0012:
gegen python3 lv.py 803 300 0.0012:
Ein Kaninchen weniger am Anfang macht hundert Schritte später plötzlich
so ein gedrängeltes, langsames Wachstum.
Warum ich gerade bei 0.0012 geschaut habe? Nun ich wollte einen
Überblick über das Verhalten bei verschiedenen Tödlichkeiten und habe
darum stability_by_deadliness.py geschrieben, das einfach ein paar
interessante Tödlichkeiten durchprobiert und dann die relative
Schwankung (in Wirklichkeit: Standardabweichung durch Mittelwert) und
den Mittelwert der Population über der Virustödlichkeit aufträgt:
– das sieht sehr gut aus für meine These: Mit wachsender Tödlichkeit
des Virus nimmt die relative Streuung der Population ab, irgendwann
allerdings auch die Population selbst. Ganz links im Graphen gehts
durcheinander, weil sich dort chaotisches Systemverhalten mit kleinen
Zahlen tifft, und dazwischen scheint es noch ein, zwei Phasenübergänge
zu geben.
Leider ist dieses Bild nicht wirklich robust. Wenn ich z.B. die
Anfangsbedingungen auf 600 Gras und 250 Kaninchen ändere, kommt sowas
raus:
– die meisten der Effekte, die mich gefreut haben, sind schwach oder gar
ganz weg – wohlgemerkt, ohne Modelländerung, nur, weil ich zwei
(letztlich) Zufallszahlen geändert habe.
Mit etwas Buddeln findet mensch auch das Umgekehrte: wer immer mit 170
Gras und 760 Kaninchen anfängt, bekommt einen Bereich, in dem die
Populationen mit Virus größer sind als ohne, während gleichzeitig die
relative Schwankung nur noch halb so groß ist wie ohne Virus.
Dazwischen liegt ein 1a Phasenübergang:
Mensch ahnt: da steckt viel Rauschen drin, und auf der anderen Seite
höchst stabiles Verhalten, wo mensch es vielleicht nicht erwarten würde
(bei den hohen Tödlichkeiten und mithin kleinen Zahlen). Wissenschaft
wäre jetzt, das systematisch anzusehen (a.k.a. „Arbeit“). Das aber ist
für sehr ähnliche Modelle garantiert schon etliche Male gemacht worden,
so dass der wirklich erste Schritt im Jahr 51 nach PDP-11 erstmal
Literatur-Recherche wäre.
Dazu bin ich natürlich zu faul – das hier ist ja nicht mein Job.
Aber das kleine Spiel hat meine Ahnung – Viren stabilisieren Ökosysteme
– weit genug gestützt, dass ich weiter dran glauben kann. Und doch wäre
ich ein wenig neugierig, was die Dynamische-Systeme-Leute an harter
Wissenschaft zum Thema zu bieten haben. Einsendungen?
Ich bin gestern nochmal der Sache mit den Schurken und Engeln von
neulich nachgegangen, denn auch wenn die grundsätzliche Schlussfolgerung
– wenn du Chefposten kompetetiv verteilst, kriegst du ziemlich
wahrscheinlich Schurken als Chefs – robust ist und ja schon aus der dort
gemachten qualitativen Abschätzung folgt, so gibt es natürlich doch jede
Menge interessante offene Fragen: Setzen sich Schurken drastischer durch
wenn die Engeligkeit steiler verteilt ist? Wie sehr wirkt sich der
Vorteil für die Schurken wirklich aus, vor allem, wenn sie auch nur eine
endliche Lebensdauer haben? Wie ändern sich die Ergebnisse, wenn Leute
zweite und dritte Chancen bekommen, mal wie ein richtiger Schurke
Karriere zu machen? Wie verändert sich das Bild, wenn mensch mehr
Hierarchiestufen hinzufügt?
Weil das alte Modell mit der einen Kohorte, die bei jedem Schritt um
den Faktor 2 eindampft, für solche Fragen zu schlicht ist, muss ein neues
her. Es hat den Nachteil, dass es viel mehr Code braucht als das alte –
es hat aber der Vorteil, dass es im Prinzip beliebig lang laufen kann
und über einen weiten Bereich von Parametern hinweg stationär werden
dürfte, sich also der Zustand nach einer Weile (der „Relaxationszeit“) nicht
mehr ändern sollte – natürlich vom Rauschen durch die diskrete
Simulation abgesehen. Wem also das alte Modell zu schlicht und
langweilig ist: Hier ist sunde2.py.
Das Neue
Wie sieht das Modell aus? Nun, wir haben jetzt simultan einen ganzen
Haufen N von Hierarchiestufen, die auch immer alle besetzt sind; derzeit
habe ich konstant N = 50. Von Stufe zu Stufe ändert sich jetzt die
Population nicht mehr je um einen Faktor zwei, sondern so, dass die
unterste Stufe 16-mal mehr Aktoren hat als die oberste und die
Besetzungszahl dazwischen exponentiell geht. Diese Schicht-Statistik
sollte keinen großen Einfluss auf die Ergebnisse haben, hält aber
einerseits die Zahl der zu simulierenden Aktoren auch bei tiefen
Hierarchien im Rahmen, ohne andererseits auf den oberen Ebenen die ganze
Zeit mit allzu kleinen Zahlen kämpfen zu müssen.
Aktoren haben jetzt auch ein Alter; sie sterben (meist) nach L ⋅ N
Runden; L kann interpretiert werden als die Zahl der Versuche pro
Wettbewerb, die ein Aktor im Mittel hat, wenn er ganz nach oben will. Im
Code heißt das lifetime_factor (hier: Lebenzeit-Faktor), und ich
nehme den meist als 2 („vita brevis“).
Es gibt eine Ausnahme auf der strikten Lebenszeitbegrenzung: Wenn ein
Level sich schon um mehr als die Hälfte geleert hat, überleben die, die
noch drin sind, auch wenn sie eigentlich schon sterben müssten. An sich ist
diese künstliche Lebensverlängerung nur ein technischer Trick, damit mir
der Kram mit ungünstigen Parametern und bei der Relaxation nicht auf
interessante Weise um die Ohren fliegt; es kann nämlich durchaus sein,
dass die oberen Ebenen „verhungern“, weil Aktoren schneller sterben als
befördert werden. Er hat aber den interessanten Nebeneffekt, dass
speziell in Modellen mit kleinem L wie in der Realität die
Lebenserwartung der höheren Klassen höher ist als die der unteren.
Um die Gesamtzahl der Aktoren konstant zu halten, werden in jeder Runde
so viele Aktoren geboren wie gestorben sind, und zwar alle in die
niedrigste Schicht.
Das enspricht natürlich überhaupt nicht der Realität – schon die Zahlen
zur Bildungsbeteiligung gegen Ende des Posts Immerhin gegen Ende zeigen ja,
dass viele Menschen mitnichten bei Null anfangen in ihrem
gesellschaftlichen Aufstieg. Insofern hätte mensch darüber nachdenken
können, bestehende Aktoren irgendwie fortzupflanzen. Das aber hätte
eine Theorie zum Erbgang von Schurkigkeit gebraucht (die auch dann nicht
einfach ist, wenn mensch wie ich da wenig oder keine biologische
Komponenten vermutet) und darüber hinaus den Einbau von Abstiegen in der
Hierarchie erfordert.
Die zusätzliche Komplexität davon wäre jetzt nicht dramatisch gewesen,
aber das kontrafaktische „alle fangen bei Null an“ residiert als
„Chancengleichheit“ auch im Kern der modernen Wettbewerbsreligion. Für
ein Modell – das ohnehin in einer eher lockeren Beziehung zur
Wirklichkeit steht – ist sie daher genau richtig. Sollten übrigens in
der Realität Kinder von eher schurkigen Menschen auch tendenziell eher
schurkig werden, würde das die Anreicherung von Schurkigkeit gegenüber
dem chancengleichen Modell nur verstärken.
Das Alte
Der Rest ist wie beim einfachen Modell: da es gibt den
Schurken-Vorteil, die Wahrscheinlichkeit, dass ein Aktor, der gerade
schurkig ist, gegen einen, der gerade engelig ist, gewinnt. Dieser
rogue_advantage ist bei mir in der Regel 0.66.
Der letzte Parameter ist die Verteilung der Schurkigkeit (also der
Wahrscheinlichkeit, dass sich ein Aktor in einem Wettbewerb als Schurke
verhält). Dazu habe ich wie zuvor eine Gleichverteilung,
Exponentialverteilungen der Schurkigkeit mit verschidenen λ (also:
gegenüber der Gleichverteilung sind mehr Aktoren Engel, wobei die
allerdings alle Schurkeigkeiten über 1 auf 1 beschnitten werden; für
kleine λ wird das also schwer zu interpretieren) und Normalverteilungen
reingebaut, dieses Mal aber viel expliziter als im einfachen Modell des
letzten Posts.
Ich hatte eigentlich vor, den Kram immer laufen zu lassen, bis er
„stationär“ würde, also sagen wir, bis der Schurkigkeits-Gradient in den
mittleren Schichten sich von Runde zu Runde nicht mehr wesentlich
ändert. Stellt sich aber raus: durch die relativ überschaubaren
Aktor-Zahlen und die Dynamik der Gesellschaft, in der ja per Design viel
Aufstieg stattfindet, rauschen die Metriken, die ich da probiert habe,
zu stark, um guten Gewissens sagen zu können, jetzt sei das Ding
relaxiert (im Code: DiffingWatcher).
Was passiert?
Stattdessen lasse ich die Modelle jetzt erstmal laufen, bis die
(gleichverteilte) Anfangspopulation weitgehend ausgestorben ist (nämlich
N ⋅ L Runden) und ziehe dann nochmal für N ⋅ L Runden Statistiken,
vor allem die mittlere Schurkigkeit in Abhängigkeit von der
Hierarchieebene. Die kann ich dann übereinanderplotten, wobei ich die
Zeit durch den Grauwert einfließen lasse (spätere, wahrscheinlich etwas
relaxiertere, Zustände sind dunkler):
Dabei ist auf der Abszisse die mittlere Hierarchieebene, auf der
Ordinate die mittlere Schurkigkeit auf der entsprechenden Ebene; die
Zeit ist, wie gesagt, durch den Grauwert der Punkte angedeutet und sorgt
für die Streuung.
Am auffälligsten ist wohl, dass Schurkigkeit auf den letzten paar Stufen
am drastischsten ansteigt. Das hätte ich in dem Ausmaß nicht erwartet
und deckt sich jedenfalls nach meiner Erfahrung nicht mit irgendwelchen
Realitäten (in denen die Schurkigkeit schon auf nur moderat
schwindelerregenden Ebenen rapide wächst). Ich komme gegen Ende nochmal
etwas quantitativer auf die Steilheit des Anstiegs zurück.
Hier, wie auch sonst, sind die Modelle bezeichnet durch einen String
– sunde2.py verwendet ihn als Dateinamen –, der aus einer Bezeichnung
der Verteilung (hier Exponential mit λ=4), der Zahl der Level N,
dem Schurken-Vorteil und dem Lebenszeit-Faktor L besteht.
Eine andere Art, diese Daten anzusehen, die insbesondere etwas mehr von
der Dynamik erahnen lässt, ist eine Heatmap der Schurkigkeit; hier
laufen die Hierarchieebenen auf der Ordinate, die Zeit auf der Abszisse;
aus Bequemlichkeitsgründen hat hier die höchste Ebene mal die
Bezeichnung 0 (so ist das übrigens auch im Programm gemacht, in den anderen
Grafiken ist dagegen Ebene 50 das Nüßlein-Territorium):
In-joke: Regenbogen-Palette. Ich habe gerade frei, ich darf das.
Hier lässt sich ganz gut erkennen, dass der Kram nach einer maximalen
Lebensdauer (da fängt die Grafik an) weitgehend relaxiert ist, und
wieder, dass die letzten paar Hierarchieebenen die dramatischsten
Schurken-Konzentrationen aufweisen. Die schrägen Strukturen, die
überall sichtbar sind, sind zufällige Schurken-Konzentrationen auf der
Karriereleiter. Intuitiv wäre wohl zu erwarten, dass sich Engel in
Haifischbecken eher noch schwerer tun und so Schurkigkeitszonen
selbstverstärkend sein könnten. Insofern ist die relativ geringe
Streifigkeit der Grafik – die sagt, dass das wenigstens im Modell nicht
so ist – erstmal eher beruhigend.
Umgekehrt bilde mich mir ein, dass im unteren Bereich der Grafik einige
blauere (also: engeligere) Strukturen deutlich flacher als 45 Grad
laufen: Das könnten Engel-Konzentrationen sein, die gemeinsam langsamer
die Karriereleiter besteigen. Fänd ich putzig (wenns die Karriereleiter
denn schon gibt), kann aber auch nur überinterpretiertes Rauschen sein.
Und noch eine Auswertung von diesem spezifischen Modell: Alter über
Hierarchieebene, was angesichts des aktuellen
Alte-weiße-Männer-Diskurses vielleicht interessant sein mag:
Diese Abbildung funktioniert so wie die der mittleren Schurkigkeit, nur
ist auf der Ordinate jetzt das Alter statt der Schurkigkeit. In dem
Modell leben Aktoren ja zwei Mal die Zahl der Hierarchieebenen Runden,
hier also 100 Runden. Die Aktoren ganz unten sind erkennbar deutlich
jünger als der Schnitt (der bei 50 liegt), ganz oben sammeln sich alte
Aktoren. Klingt speziell in dieser Ausprägung, in der oben wirklich nur
Aktoren kurz vom Exitus sind, irgendwie nach später Sowjetunion, und
klar ist das Modell viel zu einfach, um etwas wie die City of London
zu erklären.
Note to self: Beim nächsten Mal sollte ich mal sehen, wie sich das
mittlere Alter von Schuken und Engeln in den unteren Schichten so
verhält.
Mal systematisch
Weil Simulationen dieser Art schrecklich viele Parameter haben, ist das
eigentlich Interessante, den Einfluss der Parameter auf die Ergebnisse
zu untersuchen. Dazu habe ich mir mal ein paar Modelle herausgesucht,
die verschiedene Parameter variieren (in der run_many-Funktion von
sunde2); Ausgangspunkt sind dabei 50 Ebenen mit einem Lebenszeit-Faktor
von zwei und einem Schurkenvorteil von 0.66. Das kombiniere ich
mit:
einer Gleichverteilung von Schurkigkeiten
einer Exponentialverteilung mit λ = 2
einer Exponentialverteilung mit λ = 4
einer Exponentialverteilung mit λ = 4, aber einem Schurkenvorteil von
0.75
einer Exponentialverteilung mit λ = 4, aber einem Lebenszeit-Faktor von 4
Die gerade durch die Medien gehende Geschichte von Georg Nüßlein
zeichnet, ganz egal, was an Steuerhinterziehung und
Bestechung nachher übrig bleibt,
jedenfalls das Bild von einem Menschen, der, während rundrum
die Kacke am Dampfen ist, erstmal überlegt, wie er da noch den einen
oder anderen Euro aus öffentlichen Kassen in seine Taschen wandern
lassen kann.
Die Unverfrorenheit mag verwundern, nicht aber, dass Schurken in
die Fraktionsleitung der CSU aufsteigen. Im Gegenteil – seit ich
gelegentlich mal mit wichtigen Leuten umgehe, fasziniert mich die
Systematik, mit der die mittlere Schurkigkeit von Menschen mit ihrer
Stellung in der Hierarchie steil zunimmt: Wo in meiner unmittelbaren
Arbeitsumgebung eigentlich die meisten Leute recht nett sind, gibt es
unter den Profen schon deutlich weniger Leute mit erkennbarem Herz. Im
Rektorat wird es schon richtig eng, und im Wissenschaftsministerium
verhalten sich oberhalb der Sekretariate eigentlich alle wie Schurken,
egal ob nun früher unter Frankenberg oder jetzt unter Bauer.
Tatsächlich ist das mehr oder minder zwangsläufig so in Systemen, die
nach Wettbewerb befördern. Alles, was es für ein qualitatives
Verständnis dieses Umstands braucht, sind zwei Annahmen, die vielleicht
etwas holzschnittartig, aber, so würde ich behaupten, schwer zu
bestreiten sind.
Es gibt Schurken und Engel
Wenn Schurken gegen Engel kämpfen (na ja, wettbewerben halt), haben
die Schurken in der Regel bessere Chancen.
Die zweite Annahme mag nach dem Konsum hinreichend vieler
Hollywood-Filme kontrafaktisch wirken, aber eine gewisse moralische
Flexibilität und die Bereitschaft, die Feinde (na ja, Wettbewerber halt)
zu tunken und ihnen auch mal ein Bein zu stellen, dürfte unbestreitbar
beim Gewinnen helfen.
Um mal ein Gefühl dafür zu kriegen, was das bedeutet: nehmen wir an, der
Vorteil für die Schurken würde sich so auswirken, dass pro
Hierarchieebene der Schurkenanteil um 20% steigt, und wir fangen mit 90%
Engeln an (das kommt für mein soziales Umfeld schon so in etwa hin, wenn
mensch hinreichend großzügig mit dem Engelbegriff umgeht). Als Nerd
fange ich beim Zählen mit Null an, das ist also die Ebene 0.
Auf Ebene 1 sind damit noch 0.9⋅0.8, also
72% der Leute Engel, auf Ebene 2
0.9⋅0.8⋅0.8, als knapp 58% und so fort, in Summe also 0.9⋅0.8n
auf Ebene n. Mit diesen Zahlen sind in Hierarchieebene 20 nur noch 1%
der Leute Engel, und dieser Befund ist qualitativ robust gegenüber
glaubhaften Änderungen in den Anfangszahlen der Engel oder der Vorteile
für Schurken.
Tatsächlich ist das Modell schon mathematisch grob vereinfacht, etwa
weil die Chancen für Engel sinken, je mehr Schurken es gibt, ihr Anteil
also schneller sinken sollte als hier abgeschätzt. Umgekehrt sind natürlich
auch Leute wie Herr Nüßlein nicht immer nur Schurken, sondern haben
manchmal (wettbewerbstechnisch) schwache Stunden und verhalten sich wie
Engel. Auch Engel ergeben sich dann und wann dem Sachzwang und sind von
außen von Schurken nicht zu unterscheiden. Schließlich ist wohl
einzuräumen, dass wir alle eher so eine Mischung von Engeln und Schurken
sind – wobei das Mischungsverhältnis individuell ganz offensichtlich
stark schwankt.
Eine Simulation
All das in geschlossene mathematische Ausdrücke zu gießen, ist ein
größeres Projekt. Als Computersimulation jedoch sind es nur ein paar
Zeilen, und die würde ich hier gerne zur allgemeinen Unterhaltung und
Kritik veröffentlichen (und ja, auch die sind unter CC-0).
Ein Ergebnis vorneweg: in einem aus meiner Sicht recht
plausiblen Modell verhält sich die Schurkigkeit (auf der Ordinate; 1
bedeutet, dass alle Leute sich immer wie Schurken verhalten) über der
Hierarchiebene (auf der Abszisse, höhere Ebenen rechts) wie folgt (da
sind jeweils mehrere Punkte pro Ebene, weil ich das öfter habe laufen
lassen):
Ergebnis eines Laufs mit einem Schurken-Vorteil von 0.66, mittlere
Schurkigkeit über der Hierarchieebene: Im mittleren Management ist
demnach zur 75% mit schurkigem Verhalten zu rechnen. Nochmal ein paar
Stufen drüber kanns auch mal besser sein. Die große Streuung auf den
hohen Hierarchieebenen kommt aus den kleinen Zahlen, die es
da noch gibt; in meinen Testläufen fange ich mit 220 (also
ungefähr einer Million) Personen an und lasse die 16 Mal Karriere
machen; mithin bleiben am Schluss 16 Oberchefs übrig, und da macht
ein_e einzige_r Meistens-Engel schon ziemlich was aus.
Das Programm, das das macht, habe ich Schurken und Engel getauft,
sunde.py – und lade zu Experimenten damit ein.
Es wird also festgelegt, dass, wenn ein Schurke gegen einen Engel
wettbewerbt, der Schurke mit zu 66% gewinnt (und ich sage mal voraus,
dass der konkrete Wert hier qualitativ nicht viel ändern wird), während
es ansonsten 50/50 ausgeht. Das ist letztlich das, was in _WIN_PROB
steht.
Und dann gibt es das Menschenmodell: Die Person wird, wir befinden uns
in gefährlicher Nähe zu Wirtschafts„wissenschaften“, durch einen
Parameter bestimmt, nämlich die Engeligkeit (angelicity; das Wort gibts
wirklich, meint aber eigentlich nicht wie hier irgendwas wie
Unbestechlichkeit). Diese ist die Wahrscheinlichkeit, sich anständig zu
verhalten, so, wie das in der is_rogue-Methode gemacht ist: Wenn
eine Zufallszahl zwischen 0 und 1 (das Ergebnis von random.random())
großer als die Engeligkeit ist, ist die Person gerade schurkig.
Das wird dann in der wins_against-Methode verwendet: sie bekommt
eine weitere Actor-Instanz, fragt diese, ob sie gerade ein Schurke ist,
fragt sich das auch selbst, und schaut dann in _WIN_PROB nach, was
das für die Gewinnwahrscheinlichkeit bedeutet. Wieder wird das gegen
random.random() verglichen, und das Ergebnis ist, ob self gegen
other gewonnen hat.
Der nächste Schritt ist die Kohorte; die Vorstellung ist mal so ganz in
etwa, dass wir einem
Abschlussjahrgang bei der Karriere folgen. Für jede Ebene gibt es eine
Aufstiegsprüfung, und wer die verliert, fliegt aus dem Spiel. Ja, das
ist harscher als die Realität, aber nicht arg viel. Mensch fängt mit
vielen Leuten an, und je weiter es in Chef- oder Ministerialetage geht,
desto dünner wird die Luft – oder eher, desto kleiner die actor-Menge:
class Cohort:
draw = random.random
def __init__(self, init_size):
self.actors = set(Actor(self.draw())
for _ in range(init_size))
def run_competition(self):
new_actors = set()
for a1, a2 in self.iter_pairs():
if a1.wins_against(a2):
new_actors.add(a1)
else:
new_actors.add(a2)
self.actors = new_actors
def get_meanness(self):
return 1-sum(a.angelicity
for a in self.actors)/len(self.actors)
(ich habe eine technische Methode rausgenommen; für den vollen Code vgl.
oben).
Interessant hier ist vor allem das draw-Attribut: Das zieht nämlich
Engeligkeiten. In dieser Basisfassung kommen die einfach aus einer
Gleichverteilung zwischen 0 und 1, wozu unten noch mehr zu sagen sein
wird. run_competition ist der Karriereschritt wie eben beschrieben,
und get_meanness gibt die mittlere Schurkigkeit als eins minus der
gemittelten Engeligkeit zurück. Diesem Wortspiel konnte ich nicht
widerstehen.
Es gäbe zusätzlich zu meanness noch interessante weitere Metriken, um
auszudrücken, wie schlimm das Schurkenproblem jeweils ist,
zum Beispiel: Wie groß ist der Anteil der Leute mit Engeligkeit unter
0.5 in der aktuellen Kohorte? Welcher Anteil von Friedrichs
(Engeligkeit<0.1) ist übrig, welcher Anteil von Christas
(Engeligkeit>0.9)? Aus wie vielen der 10% schurkgisten Personen „wird
was“? Aus wie vielen der 10% Engeligsten? Der_die Leser_in ahnt schon,
ich wünschte, ich würde noch Programmierkurse für Anfänger_innen geben:
das wären lauter nette kleine Hausaufgaben. Andererseits sollte mensch
wahrscheinlich gerade in so einem pädagogischen Kontext nicht
suggerieren, dieser ganze Metrik-Quatsch sei unbestritten. Hm.
Nun: Wer sunde.py laufen lässt, bekommt Paare von Zahlen
ausgegeben, die jeweils Hierarchiestufe und meanness der Kohorte angeben.
Die kann mensch dann in einer Datei sammeln, etwa so:
und so fort. Und das Ganze lässt sich ganz oldschool mit gnuplot
darstellen (das hat die Abbildung oben gemacht), z.B. durch:
plot "results.txt" with dots notitle
auf der gnuplot-Kommandozeile.
Wenn mir wer ein ipython-Notebook schickt, das etwa durch matplotlib
plottet, veröffentliche ich das gerne an dieser Stelle – aber ich
persönlich finde shell und vi einfach eine viel angenehmere Umgebung...
Anfangsverteilungen
Eine spannende Spielmöglichkeit ist, die Gesellschaft
anders zu modellieren, etwa durch eine Gaußverteilung der Engeligkeit,
bei der die meisten Leute so zu 50% halb Engel und halb Schurken sind
(notabene deckt sich das nicht mit meiner persönlichen Erfahrung, aber
probieren kann mensch es ja mal).
Dazu ersetze ich die draw-Zuweisung in Cohort durch:
Die „zwei Sigma“, also – eine der wichtigeren Faustformeln, die
mensch im Kopf haben sollte – 95% der Fälle, liegen hier zwischen 0 und
1. Was drüber und drunter rausguckt, wird auf „immer Engel“ oder „immer
Schurke“ abgeschnitten. Es gibt in diesem Modell also immerhin 2.5%
Vollzeitschurken. Überraschenderweise sammeln sich die in den ersten 16
Wettbewerben nicht sehr drastisch in den hohen Chargen, eher im
Gegenteil:
Deutlich plausibler als die Normalverteilung finde ich in diesem Fall ja
eine …
After decades of (essentially) using other people's smarthosts to send
mail, I have recently needed to run a full-blown, deliver-to-the-world
mail server (cf. Das Fürchten lernen; it's in German, though).
While I had expected this to be a major nightmare, it turns out it's not so
bad at all. Therefore I thought I'd write up a little how-to-like thing –
perhaps it will help someone to set up their own mail server. Which
would be a good thing. Don't leave mail to the bigshots, it's too
important for that.
Preparation
You'll want to at least skim the exim4 page on the Debian wiki as
well as /usr/share/doc/exim4/README.Debian.gz on your box. Don't
worry if any of that talks about things you've never heard about at this
point and come back here.
The most important thing to work out in advance is to get your DNS to
look attractive to the various spam estimators; I didn't have that
(mostly because I moved “secondary” domains first), which caused a lot
of headache (that article again is in German).
How do you look attractive? Well, in your DNS make sure the PTR for
your IP is to mail.<your-domain>, and make sure
mail.<your-domain> exists and resolves to that IP or a CNAME
pointing there. Note that this means that you can forget about running a
mail server on a dynamic IP. But then dynamic IPs are a pain anyway.
Before doing anything else, wait until the TTL of any previous records
of this kind has expired. Don't take this lightly, and if you don't
unterstand what I've been saying here, read up on DNS in the
meantime. You won't have much joy with your mail server without a
reasonable grasp of reverse DNS, DNS caching, and MX records.
Use the opportunity to set the TTL of the MX record(s) for your
domain(s) to a few minutes perhaps. Once you have configured your mail
system, you can then quickly change where other hosts will deliver their
mail for your domain(s) and raise the TTLs again.
Exim4
Debian has come with the mail transfer agent (MTA; the mail server
proper if you will) exim4 installed by default for a long, long time,
and I've been using it on many boxes to feed the smart hosts for as long
as I've been using Debian. So, I'll not migrate to something else
just because my mail server will talk to the world now. Still, you'll
have to dpkg-reconfigureexim4-config. Much of what's being asked
by that is well explained in the help texts. Just a few hints:
“General type of mail configuration” would obviously be “internet site“.
Mail name ought to be <your domain>; if you have multiple domains,
choose the one you'd like to see if someone mails without choosing
any.
Keep the IP addresses to listen on empty – you want other hosts
to deliver mail on port 25. Technically, it would be enough to listen
only on the address your MX record points to, but that's a
complication that's rarely useful.
Relaying mail for non-local domains is what you want if you want to be
a smart host yourself. You'll pretty certainly want to keep this
empty as it's easy to mess it up, and it's easy to configure
authenticated SMTP even on clients (also see client connections on
avoiding authenticated SMTP on top).
Exim also is a mail delivery agent (MDA), i.e., something that will
put mail for domains it handles into people's mail boxes. I'll assume
below that you select Maildir format in home directory as the
delivery method. Maildir is so much cooler than the ancient mboxes,
and whoever wants something else can still use .forward or procmail.
And do split your configuration into small files. Sure, you'll have
to remember to run update-exim4.conf after your edits, but that litte
effort will be totally worth it after your next dist-upgrade, when you
won't have to merge the (large) exim4 config file manually and figure
out what changes you did where.
DNS Edits
With this, you should be in business for receiving mail. Hence, make
your MX record point to your new mail server. In an NSD zone file (and
NSD is my choice for running my DNS server), this could look like:
<your domain>. IN MX 10 <your domain>.
(as usual in such files: Don't forget the trailing dots).
A couple of years ago, it was all the craze to play games with having
multiple MX records to fend off spam. It's definitely not worth it any
more.
While I personally think SPF is a really bad idea, some spam filters
will regard your mail more kindly if they find an SPF record. So,
unless you have stronger reasons to not have one than just “SPF is a
bad concept and breaks sane mailing list practices, .forward files and
simple mail bouncing”, add a record like this:
<your domain>. 3600 IN TXT "v=spf1" "+mx" "+a" "+ip4:127.0.0.1" "-all"
– where you have to replace the 127.0.0.1 with your IP and perhaps add a
similar ip6 clause. What this means: Mail coming from senders in <your
domain> ought to originate at the IP(s) given, and when it comes from
somewhere else it's fishy. Which is why this breaks good mailing list
practices. But forunately most spam filters know that and don't
interpret these SPF clauses to narrow-mindedly.
SSL
I'm not a huge fan of SSL as a base for cryptography – X.509 alone is
scary and a poor defense against state actors –, but since it's 2021,
having non-SSL services doesn't look good. Since it's important to look
good so people accept your mail, add SSL to your exim installation.
Unless you can get longer-living, generally-trusted SSL certificates
from somewhere else, use letsencrypt certificates. Since (possibly
among others) the folks from t-online.de want to see some declaration
who is behind a mail server on such a web site, set up a web server for
mail.<your-domain> and obtain letsencrypt SSL certificates for them
in whatever way you do that.
Then, in the post-update script of your letsencrypt updater, run
something like:
(which of course assumes that script runs as root or at least with
sufficient privileges). /etc/exim4/ssl you'll have to create
yourself, and to keep your key material at least a bit secret, do a:
– that way, exim can read it even if it's already dropped its
privileges, but ordinary users on your box cannot.
Then tell exim about your keys. For that, use some file in
/etc/exim4/conf.d/main; such files are the main way of configuring the
exim4 package in non-trivial ways. I have 00_localmacros, which
contains:
Then, do the usual update-exim4.conf && service exim4 restart, and
you should be able to speak SSL with your exim. The easiest way to test
this is to install the swaks package (which will come in useful when
you want to run authenticated SMTP or similar, too) and then run:
swaks -a -tls -q HELO -s mail.<your domain> -au test -ap '<>'
This will spit out the dialogue with your mail server and at some point
say 220 TLS go ahead or so if things work, some more or less helpful
error message if not.
Aliases
Exim comes with the most important aliases (e.g., postmaster)
pre-configured in /etc/aliases. If you want to accept mail for people
not in your /etc/passwd, add them there.
The way this is set up, exim ignores domains; if you told exim to accept
mails for domain1.de and domain2.fi, then mail to both user@domain1.de
and user@domain2.fi will end up in /home/user/Maildir (or be
rejected if user doesn't exist and there's no alias either). If you
want to have domain-specific handling, add a file
/etc/exim4/forwards that contains pairs like:
drjekyll@example.org: mrhyde@otherexample.org
The standard Debian configuration of Exim will not evaluate this file;
to make it do that, drop a file wil something like:
# Route using a global incoming -> outgoing alias file
global_aliases:
debug_print = "R: global_aliases for $local_part@$domain"
driver = redirect
domains = +local_domains
allow_fail
allow_defer
data = ${lookup{$local_part@$domain}lsearch{/etc/exim4/forwards}}
into (say) /etc/exim4/conf.d/router/450_other-aliases. After the
usual update-exim4.conf, you should be good to go.
Client Connections
This setup only accepts mail for transport locally, and it will only
deliver locally. That is: This isn't a smarthost setup yet.
For delivery from remote systems, we're using ssh because pubkey auth is
cool. This even works from an exim on the remote system …
![[RSS]](../theme/image/rss.png)