![[RSS]](../theme/image/rss.png)
Alte Tiefpunkte bei Vodafone: Irreführende Werbung auf Port 80

Auch (von hier aus gesehen) am anderen Ende der Welt ist es schwer, Vodafone zu entkommen[1]. Dieser Post erzählt eine von vielen Geschichten, die nahelegen, es dennoch zu versuchen.
Unter Telekommunizierenden gibt es fast weltweit ein Sprichwort: „Gib Vodafone den kleinen Finger und sie nehmen deinen ganzen Arm, um dich aufs Kreuz zu legen.“
Auf Vodafone gekommen
Ich kannte dieses Sprichwort natürlich, als neulich das Unternehmen, über das mein Rechner im Notfall Internet-Verbindungen aufbaute – ein Drillisch-Zwischenhändler, also „E-Netz“ –, aus dem Geschäft mit grundgebührenfreien Prepaid-Karten ausgestiegen ist. Tja: Vodafone bietet immer noch Prepaid an, und zwar mit aus meiner Sicht eher günstigen 3 Cent fürs Megabyte.
Wer den Kopf angesichts solcher Preise schüttelt, da es doch für 10 Euro auch 10 GB gäbe: nun, ich übertrage in starken Monaten 20 MB über GSM oder LTE, und das kann ich so für 60 Cent machen. Für mich war sogar Prepaid für 9 ct/MB (hatte ich vorher) ein guter Deal.
Ich hatte zusätzlich die Fantasie, dass ich im ehemaligen D2-Netz endlich ordentliche Netzabdeckung haben würde, denn die war bei den E-Netz-Erben von Drillisch eher unterhalb von la-la. Auch wenn das nicht meine aktuelle Geschichte ist, merke ich an, dass das nach meinem ersten Eindruck eine Fantasie bleibt: In einem fahrenden Zug in Oberbayern hatte ich im Groben nur in den Bahnhöfen Netz. Aber das mag an LTE und meiner etwas antiken Karte (eine Sierra EM7345) gelegen haben; auf der Rückfahrt hatte ich sie auf GSM eingebremst, und es sah deutlich besser aus mit der Konnektivität.
Meine Gewissheit, dass mich der Kontakt mit Vodafone unglücklich machen würde, hat sich allerdings in anderer Weise bewahrheitet.
Gefährlicher Eingriff in die Telekommunikation
Vodafone nämlich erdreistet sich, ihren zahlenden KundInnen irreführende Werbung in die Leitung zu drücken, wenn sie das können. Na gut: Sie haben noch nicht entdeckt, dass sie auch in unverschlüsselte POP-Verbindungen eingreifen könnten, um ihren Opfern gefälschte E-Mails unterzujubeln. Also: ich glaube, dass sie das noch nicht entdeckt haben, denn mein POP-Client prüft Zertifikate.
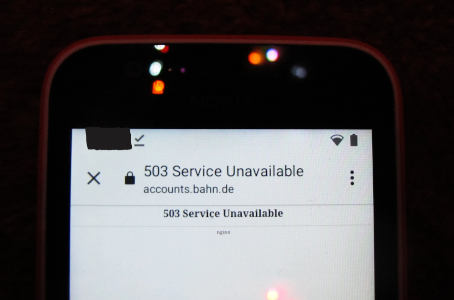
Aber doch, wirklich: Vodafone fängt mit meinem CallYa-Tarif („Classic“) meistens (die volle Systematik habe ich noch nicht ganz überrissen) Verbindungen zu Port 80 (also: http) zu beliebigen Servern ab und gibt statt der bestellten Daten HTML für höchst schmierige Werbung zurück. Menschen, die Computerisch erschreckt, können den folgenden Block ohne große Verluste überspringen, aber weil ich dieses Verhalten so unfassbar dreist finde, wollte ich zumindest dokumentiert haben, zu welchen Schandtaten Vodafone bereit ist:
$ curl -vL http://blog.tfiu.de * Trying 116.203.206.117:80... * Connected to blog.tfiu.de (116.203.206.117) port 80 (#0) > GET / HTTP/1.1 > Host: blog.tfiu.de > User-Agent: curl/7.88.1 > Accept: */* > < HTTP/1.1 200 OK < Date: Sat, 22 Feb 2025 12:29:42 GMT < Server: Apache < Upgrade: h2 < Connection: close < Accept-Ranges: bytes < Pragma: no-cache < Cache-Control: private, no-cache, no-store, must-revalidate, max-age=0, no-transform < Expires: Tue, 09 Feb 1982 08:12:00 GMT < X-VFCENTER-Redirector: Frontend < Via: 1.1 center.vodafone.de < Transfer-Encoding: chunked < Content-Type: text/html; charset=utf-8 < <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//WAPFORUM//DTD XHTML Mobile 1.1//EN" "http://www.openmobilealliance.org/tech/DTD/xhtml-mobile11.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head><title>Vodafone Center</title> <meta http-equiv="Cache-Control" content="no-cache"/> <meta http-equiv="refresh" content="1;URL=https://center.vodafone.de/vfcenter/index.html?targetUrl=http%3A%2F%2Fblog.tfiu.de/"/> <style type="text/css">[...]</style></head> <body><h1>Sie werden weitergeleitet ...</h1> <p>Sollten Sie nicht weitergeleitet werden, klicken Sie bitte <a href="https://center.vodafone.de/vfcenter/index.html?targetUrl=targetUrl=http%3A%2F%2Fblog.tfiu.de/">hier</a>.</p></body></html> * Closing connection 0
(für bessere Lesbarkeit habe ich ein paar Zeilenumbrüche eingefügt). Übersetzt in normale Sprache ist das: Vodafone entführt meinen treudoofen Browser einfach auf eines ihrer Dokumente, statt meine Anfrage an den von mir gewünschten Server zu transportieren. Sowas heißt Man-in-the-Middle-Angriff. Finde nur ich seltsam, dass Vodafone seine eigenen zahlenden KundInnen angreift?
Schlechtes Gewissen und Murks
Immerhin haben sie dabei offenbar etwas schlechtes Gewissen:
Cache-Control: private, no-cache, no-store, must-revalidate, max-age=0, no-transform
ist ein Versuch, Browsern, Proxies und ähnlichen Programmen zu sagen, dass sie bei einem neuen Versuch nicht einfach nochmal das dreiste Entführungsdokument verwenden sollen. An sich ist das richtig und gut, aber Vodafone wäre nicht Vodafone, wenn nicht auch das wacklig wäre; im HTML steht:
<meta http-equiv="Cache-Control" content="no-cache"/>
– und das heißt so viel wie: „setze den Cache-Control-Header auf no-cache“. Was der arme User Agent (also euer Browser) wohl tun soll, wenn sich HTTP-Header und Angabe im HTML-Dokument nicht einig sind? Und natürlich stellt sich die Frage, warum das Dokument mit einem HTTP-Statuscode von 200 („alles in Ordnung, hier sind deine Daten“) ausgeliefert wird, wenn es doch nicht mehr ist als ein Redirect, für den ein 303 See Also angemessener wäre. Also, wenn das nicht ohnehin alles eine Infamie wäre.
Mensch beachte weiter das hier:
<meta http-equiv="refresh" content="1;URL=https://center.vodafone.de/vfcenter/index.html?targetUrl=http%3A%2F%2Fblog.tfiu.de/"/> [...] <p>Sollten Sie nicht weitergeleitet werden, klicken Sie bitte <a href="https://center.vodafone.de/vfcenter/index.html?targetUrl=targetUrl=http%3A%2F%2Fblog.tfiu.de/" >hier</a>.</p></body></html>
Die eigentliche Ziel-URL soll also der Werbeseite mitgeteilt werden, vermutlich, weil mal geplant war, dass mensch von dort irgendwie zur eigentlich gewünschten Webseite weiterkommt.
Das könnte in der Angabe im Meta-Element (erste Zeile) auch klappen, bei dem hinreichend vertrauensselige User Agents automatisch dem Link aus einem Refresh-Pseudoheader folgen (angesichts solcher Tricks aus der Web-Steinzeit werde ich wieder jung). Weiter unten im Dokument, im p-Element, würde wer explizit auf einen Link klicken. Wenn ihr scharf schaut, seht ihr, dass die URL, auf die die Werbeseite weiterleiten könnte, targetUrl=http://blog.tfiu.de ist. Ausprobiert hat, was immer das werden sollte, bei Vodafone jedenfalls keineR, dann das würde nicht annähernd klappen.
Aber ich habe auf der fraglichen Seite ohnehin nichts gefunden, das etwas mit dieser targetUrl machen würde, und das no-cache hilft auch nicht viel, wenn beim Reload der Vodafone-Router wieder die Verbindung übernimmt und irreführende Man-in-the-Middle-Werbung ausspielt.
Irreführende Werbung
Genau: Werbung. Das, auf das Vodafone meinen Browser da schickt, ist ein dreister Versuch, den KundInnen Kram überzuhelfen, den sie nicht wollen:
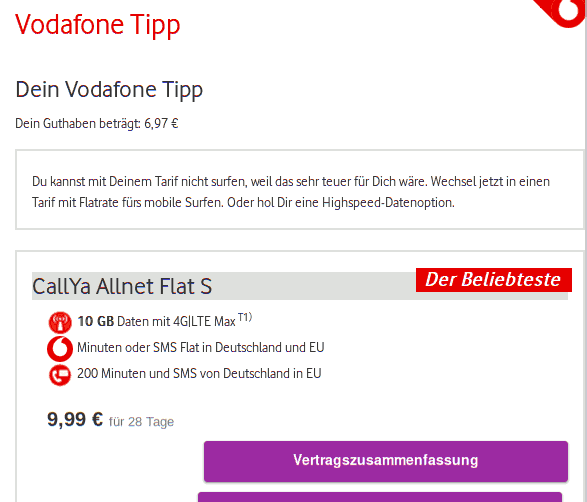
„Du kannst mit Deinem Tarif nicht surfen, weil das sehr teuer für Dich wäre.” Ja, tja, wenn das so wäre, müsste Vodafone ja auch https-Verbindungen blockieren. Was sie nicht tun – wäre ja auch noch schöner. Stattdessen wollen sie, weil sie es bei http mit einiger Aussicht können, etwas für 9.99 Euro verkaufen, weil die 30 Cent, die ich real zahle, „sehr teuer für Dich” seien. Irreführende Werbung im Extrem.
Dieses ganze juristische Risiko – Eingriff in Telekommunikation, sittenwidrige Werbung – geht Vodafone in diesen Zeiten aber ganz umsonst ein, denn eigentlich haben nur noch hart gesottene Nerds http-Verbindungen (zum Beispiel wegen). Alle anderen hat Google auf https umgezogen, und zwar, wie Shoshana Zuboff in ihrem Age of Surveillance Capitalism recht überzeugend darlegt, wegen Praktiken, die denen von Vodafone ziemlich ähnlich waren: In den USA hatte Verizon irgendwann um 2010 angefangen, in http-Verbindungen ihrer Opfer^WKundInnen Spyware zu schmuggeln, die Googles Monopol auf Überwachungsmehrwehrt gefährdete.
Dass Edward Snowdens Enthüllungen, an die sich viele Menschen als Anlass für die großräumige Bewegung zu https erinnern mögen, in die gleiche Zeit fielen, war leider in Wirklichkeit mehr ein Zufall. Das war nicht Welt vs. NSA, das war Google vs. Verizon (und Google hat gewonnen).
Über ein Jahrzehnt später probiert sich Vodafone jedenfalls immer noch an den unethischen Tricks, die Verizon damals bald aufgegeben hat. Frech und technisch unsinnig.
Kommunikation mit Vodafone?
Trotz aller Vodafone-Erfahrung habe ich mich doch aufgerafft und eine Mail an die einzige Kontaktadresse, die ich ein paar Klicks von der frechen Vodafone-Werbung entfernt finden konnte, geschrieben:
To: impressum@vodafone.com
Subject: Port 80-Hijacking
Liebe Mitarbeiter/in von Vodafone,
Ich habe keine vernünftige Support-Adresse gesehen, und letztlich werfe ich hier sogar eine Rechtsfrage auf. Eigentlich reicht aber technischer Verstand, und so wäre ich dankbar, wenn Sie diese Mail erstmal an Personen weiterleiten könnten, die wissen, wovon ich hier rede.
Also: Bevor ich wegen etwas, das für Sie eine Lappalie ist, zur Verbraucherzentrale gehe, wollte ich Sie bitten, das Hijacking von Port 80 bei CallYa sein zu lassen, also die Unsitte, die ersten paar HTTP-Verbindungen nach dem Verbindungsaufbau auf die Seite https://center.vodafone.de/vfcenter/index.html?targetUrl=(was-immer)&browser=web umzuleiten, auf der dann zu allem Überfluss noch irreführende Werbung der Art "Du kannst mit Deinem Tarif nicht surfen, weil das sehr teuer für Dich wäre. Wechsel jetzt in einen Tarif mit Flatrate fürs mobile Surfen. Oder hol Dir eine Highspeed-Datenoption." steht.
Das ist nicht nur ein Anspucken ihrer KundInnen (nein: ihre "Flatrates" wären für mich erheblich teuerer, und eigentlich habe ich auch keine Lust, 3 ct/MB für Ihre Werbung zu bezahlen), es ist auch fast sicher ein rechtswidriger Eingriff in Telekommuniktion …




![Screenshot der Bahnseite mit einer Meldung „Zum XX.XX.XXX werden die technischen Systeme von bahn.de umgestellt [...] Mehr Informationen finden Sie unter d2.](/media/2023/bahn-de-2023-06-11.png)










{kind=link}