![[RSS]](../theme/image/rss.png)
Carl Württemberg und die unvollständige Revolution
Immer noch bin ich mit meinem Museumspass unterwegs, doch nicht immer sind es die Gegenstände in den Ausstellungen, die die tiefsten Eindrücke hinterlassen. So war das neulich auch im württembergischen Landesmuseum (vor dem Klicken ggf. einen Blick auf ach so: die Webseite werfen) in Stuttgart. Vorausgeschickt: zwischen dem ehemaligen Kuriositätenkabinett der Potentaten des Schwabenlandes und allerlei keltischen Schätzen gibts da durchaus viel Beeindruckendes oder zumindest, tja, Kurioses.
Was nicht bleiben sollte
Den erwähnten tiefsten Eindruck hinterließ jedoch die Wand neben dem Ausgang. Dort ist nämlich eine dieser Mahntafeln zur Privatisierung gesellschaftlicher Aufgaben[1] angebracht, auf denen Menschen zur Dankbarkeit für allerlei Personen und Firmen aufgerufen werden („Logos“):

So traurig diese Beflimmerung light schon im Allgemeinen ist: dass da ein Nachkomme der alten Autokraten und Gewaltherrscher sein ultrakitschiges Herrschaftszeichen mit Krone und Spruchband („Furchtlos und treu“ – hatten wir nicht schon mehr als genug Sprüche mit „Treue“ während der letzten hundert Jahre?) im öffentlichen Raum – und dann noch ganz vorne – platzieren darf, das ist klar ein Symptom einer Demokratisierung, die allzu früh steckengeblieben ist.
Nun will ich mich nicht beschweren, dass die bis dann herrschenden Schurken 1918 ihre Köpfe behalten durften. Keine Frage, der Umgang mit Louis XVI im Jahr 1793 war selbstverständlich ein schlimmer Verstoß gegen das Prinzip RiwaFiw („Radikalität ist wichtig, aber Freundlichkeit ist wichtiger“).
Dass aber die ausgehenden FürstenInnen einen Gutteil der Dinge, die sie sich mit Feuer und Schwert von ihren Untertanen geholt hatten, behalten durften und ihnen das jetzt die Mittel gibt, Duftmarken und vermutlich auch Agenden in unseren Museen zu setzen, das ist auch ein schlimmer Verstoß gegen RiwaFiw. Die damaligen Gesetzgeber haben allzu radikal am Prinzip von Eigentum festgehalten, statt sich an einer ganz schlichten, intuitiven und freundlichen Ethik zu orientieren. Sagen wir: „was du bekommst, indem du Menschen quälst, soll zumindest diesen Menschen wieder nutzen, wenn dir die Gewaltmittel ausgehen, um deine Ansprüche durchzusetzen“.
In Sachen Schaden und Spott tritt dazu die weitere Alimentierung der Nachfahren der alten Obrigkeiten, so (vermutlich auch im württembergischen Landesmuseum) durch den „Ankauf“ von Plunder, der bereits 1918 hätte sozialisiert werden müssen.
Besonders auffällig war das im Zusammenhang mit Carl Württembergs Spießgesellen aus dem anderen Landesteil, stark archaisierend „Haus Baden“ genannt, das vor rund dreißig Jahren mit Teilen seines Tafelsilbers versuchte, das Land zu erpressen. Einen kurzen Eindruck der damaligen Debatten gibt ein Blogpost von 2006 zu diesem Thema, in dem einige FAZ-Passagen illustrieren, weshalb das weitere Gebiet der durchlauchtigen Besitztümer auch außerhalb des württembergischen Landesmuseums für schlechte Laune sorgt; diese Geschichte geht übrigens immer noch weiter, wie weitere Beiträge auf dem Blog aus dem letzten Jahrzehnt belegen.
Ach so: Die Webseite
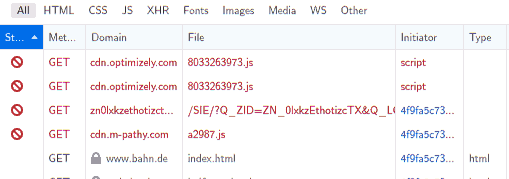
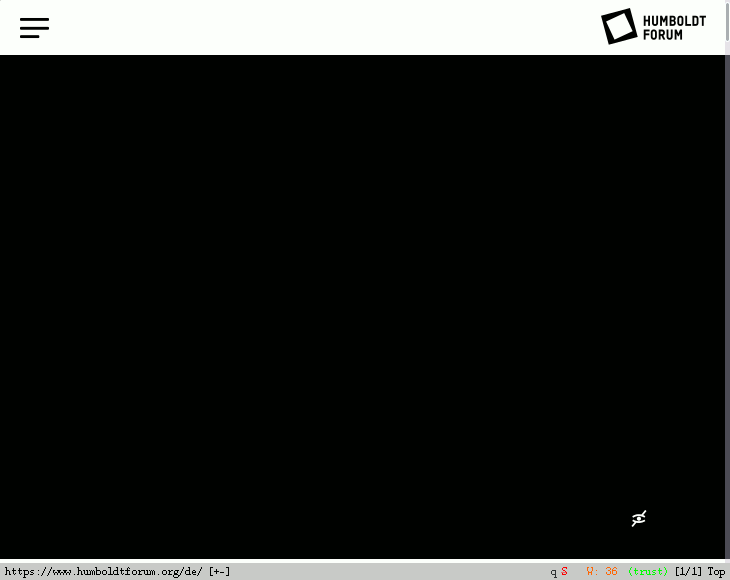
Ich kann diesesn Post nicht ohne einen scharfen Themenbruch beenden. Als ich nämlich oben aufs württembergische Landesmuseum verlinkt habe, habe ich selbstverständlich erstmal nachgesehen, was dort eigentlich steht und sah: Nichts. Alles weiß. Dabei hat die Seite eine Crapicity von gerade mal 6 (also: nur 5 Byte Digitalsoße auf 1 Byte lesbaren Text), was für kommerziell produzierte Webseiten in der heutigen Zeit an sich recht ordentlich ist.
Das hat mich milde neugierig gemacht, warum die Anzeige trotzdem so vergurkt ist. Was soll ich sagen? Es ist etwas unbedachtes CSS, das den Kram hier kaputt macht – eingestanden natürlich nur in Verbindung mit der üblichen Javascriptitis, ohne die die Zuständigen gleich selbst gesehen hätten, dass was kaputt ist. Auf reinen Textbrowsern wie wie w3m ist die Seite ordentlich nutzbar. Dillo mit seiner reduzierten CSS-Interpretation liefert ebenfalls ein brauchbares Rendering.
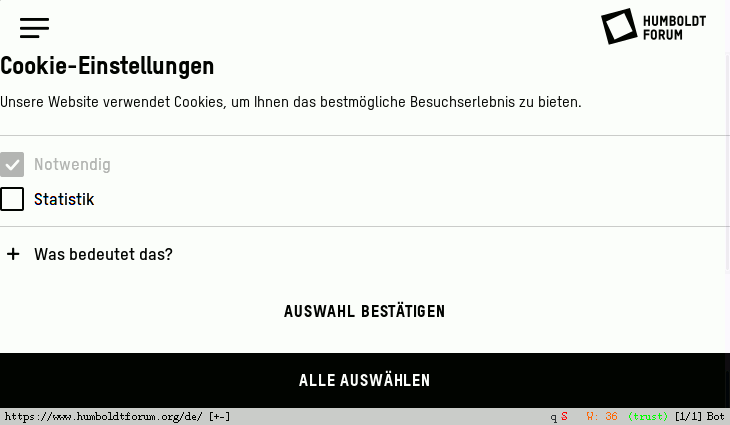
Immerhin, die Museumsleute haben offenbar ein gewisses Problembewusstsein im Hinblick darauf, dass die „großen“ Browser ihren Inhalt weiß auf weiß darstellen. Auf der Erklärung zur Barrierefreiheit des Museums heißt es nämlich:
Einige der Helligkeitskontraste sind zu klein und damit schlecht wahrnehmbar.
Das ist nicht falsch. Allerdings netto doch einen Hauch euphemistisch:

| [1] | Nun, eigentlich sind das Mahnmale der unzureichenden Besteuerung von Unternehmen und Reichen; denn offensichtlich haben die Mäzene Geld, das sie genauso gut der Gesellschaft zur Verfügung stellen (also als Steuer zahlen) könnten, mit dem sie sich jetzt aber privaten Einfluss auf öffentliche Museen kaufen. Und immerhin: hatte mensch sie ordentlich besteuert, könnten sie die Mussen nicht zwingen, ihre (also: der Museen, nicht der Mäzene) BesucherInnen mit doofen Logos und Wappen zu belästigen. |




![Screenshot der Bahnseite mit einer Meldung „Zum XX.XX.XXX werden die technischen Systeme von bahn.de umgestellt [...] Mehr Informationen finden Sie unter d2.](/media/2023/bahn-de-2023-06-11.png)