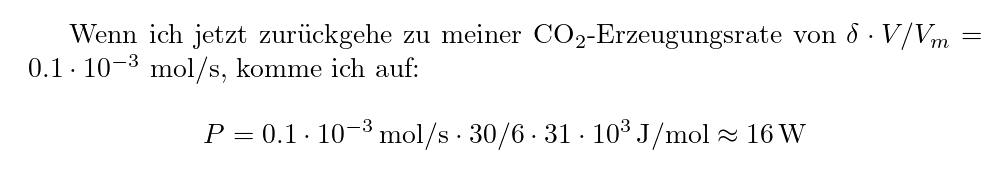I recently wrote a piece on estimating my power output from CO₂
measurements (in German) and for the first time in this blog needed to
write at least some not entirely trivial math. Well: I was seriously
unhappy with the way formulae came out.
Ugly math of course is very common as soon as you leave the lofty realms
of LaTeX. This blog is made with ReStructuredText (RST) in pelican.
Now, RST at least supports the math interpreted text role
(“inline”) and directive (“block“ or in this case rather “displayed“)
out of the box. To my great delight, the input syntax is a subset of
LaTeX's, which remains the least cumbersome way to input typeset math
into a computer.
But as I said, once I saw how the formulae came out in the browser,
my satifsfaction went away: there was really bad spacing, fractions
weren't there, and things were really hard to read.
In consequence, when writing the post I'm citing above, rather than
reading the docutils documentation to research whether the ugly
rendering was a bug or a non-feature, I wrote a footnote:
Sorry für die hässlichen Formeln. Vielleicht schreibe ich mal eine
Erweiterung für ReStructuredText, die die ordentlich mit TeX
formatiert. Oder zumindest mit MathML. Bis dahin: Danke für euer
Verständnis.
(Sorry for the ugly formulae. Perhaps one of these days I'll write
an RST extension that properly formats using TeX. Or at least MathML.
Until then: thanks for your understanding.)
This is while the documentation clearly said, just two lines below
the example that was all I had initially bothered to look at:
For HTML, the math_output configuration setting (or the corresponding
--math-output command line option) selects between alternative output
formats with different subsets of supported elements.
Following the link at least would have told me that MathML was already
there, saving me some public embarrassment.
Anyway, when yesterday I thought I might as well have a look at whether
someone had already written any of the code I was talking about in the
footnote, rather than properly reading the documentation I started
operating search engines (shame on me).
Only when those lead me to various sphinx and pelican extensions and I
peeked into their source code I finally ended up at the docutils
documentation again. And I noticed that the default math rendering was
so ugly just because I didn't bother to include the math.css
stylesheet. Oh, the miracles of reading documentation!
With this, the default math rendering suddenly turns from ”ouch” to
“might just do”.
But since I now had seen that docutils supports MathML, and since I have
wanted to have a look at it at various times in the past 20 years, I
thought I might as well try it, too. It is fairly straightforward
to turn it on; just say:
[html writers]
math_output: MathML
in your ~/.docutils (or perhaps via a pelican plugin).
I have to say I am rather underwhelmed by how my webkit renders it.
Here's what the plain docutils stylesheet works out to in my current
luakit:
And here's how it looks like via MathML:
For my tastes, the spacing is quite a bit worse in the MathML case;
additionally, the Wikipedia article on MathML mentions that the Internet
Explorer never supported it (which perhaps wouldn't bother me too much)
and that Chromium withdrew support at some point (what?). Anyway: plain
docutils with the proper css is the clear winner here in my book.
I've not evaluated mathjax, which is another option in docutils
math_output and is what pelican's render_math plugin uses. Call me a
luddite, but I'll file requiring people to let me execute almost
arbitrary code on their box just so they see math into the big folder
labelled “insanities of the modern Web”.
So, I can't really tell whether mathjax would approach TeX's quality,
but the other two options clearly lose out against real TeX, which
using dvipng would render the example to:
– the spacing is perfect, though of course the inline equation has a
terrible break (which is not TeX's fault). It hence might still be
worth hacking a pelican extension that collects all formulae, returns
placeholder image links for them and then finally does a big dvipng run
to create these images. But then this will mean dealing with a lot of
files, which I'm not wild about.
What I'd like to ideally use for the small PNGs we are talking about here
would be inline images using the data scheme, as in:
<img src="data:image/png;base64,AAA..."/>
But since I would need to create the data string when docutils calls my
extension function, I in that scheme cannot collect all the math
rendering for a single run of LaTeX and dvipng. That in turn would mean
either creating a new process for TeX and dvipng each for each piece of
math, which really sounds bad, or hacking some wild pipeline involving
both, which doesn't sound like a terribly viable proposition either.
While considering this, I remembered that matplotlib renders quite a bit
of TeX math strings, too, and it lets me render them without any
fiddling with external executables. So, I whipped up this piece of
Python:
import base64
import io
import matplotlib
from matplotlib import mathtext
matplotlib.rcParams["mathtext.fontset"] = "cm"
def render_math(tex_fragment):
"""returns self-contained HTML for a fragment of TeX (inline) math.
"""
res = io.BytesIO()
mathtext.math_to_image(f"${tex_fragment}$",
res, dpi=100, format="png")
encoded = base64.b64encode(res.getvalue()).decode("ascii")
return (f'<img src="data:image/png;base64,{encoded}"'
f' alt="{tex_fragment}" class="math-png"/>')
if __name__=="__main__":
print(render_math("\int_0^\infty \sin(x)^2\,dx"))
This prints the HTML with the inline formula, which with the example
provided looks like this:
 – ok, there's a bit too much cropping, I'd have to trick in transparency,
there's no displayed styles as far as I can tell, and clearly one would
have to think hard about CSS rules to make plausible choices for scale
and baseline – but in case my current half-satisfaction with docutils'
text choices wears off: This is what I will try to use in a docutils
extension.
– ok, there's a bit too much cropping, I'd have to trick in transparency,
there's no displayed styles as far as I can tell, and clearly one would
have to think hard about CSS rules to make plausible choices for scale
and baseline – but in case my current half-satisfaction with docutils'
text choices wears off: This is what I will try to use in a docutils
extension.
![[RSS]](../theme/image/rss.png)