![[RSS]](../theme/image/rss.png)
Saner Timestamps With DIT: In Pelican and Beyond
The other day Randall Munroe posted XKCD 2867:

This lament about time calculus struck me as something of a weird (pun alarm) synchronicity, as one evening or two before that I had written a few lines of flamboyant time-related code.
Admittedly, I was neither concerned with “sin to ask” nor with „impossible to know“: Both are a consequence of the theory of relativity, which literally states that (against Newton) there is no absolute time and hence when two clocks are in two different places, even synchronising them once is deep science.
Sold on Decimal Internet Time
No, my coding was exclusively about the entirely unnecessary trouble of having to account for time zones, daylight savings time, factors of 60, 24, sometimes 30, 31, 29, or 28, and quite a few other entirely avoidable warts in our time notation. Civil time on Earth is not complicated because of physics. On human scales of time, space, velocity, gravitation, and precision, it is not particularly hard to define an absolute time even though it physically does not exist.
Rather, civil time calculations are difficult because of the (pun alarm) Byzantine legacy from Babylon – base-60 and base-12, seven-day weeks, moon calendar – exacerbated by misguided attempts of patching that legacy up for the railway age (as in: starting in 1840, by and large done about 1920). On top of that, these patches don't work particularly well even for rail travel. I speak from recent experience in this particular matter.
Against this backdrop I was almost instantly sold on DIT, the Decimal Internet Time apparently derived from a plan a person named Anarkat (the Mastodon link on the spec page is gone now) proposed: Basically, you divide the common day in what currently is the time zone UTC-12 into 10 parts and write the result in decimal. Call the integer part “Dek” and the first two digits after the dot “Sim”. That's a globally valid timestamp precise to about a (Babylonian) minute. For example, in central Europe what's now 14:30 (or 15:30 during daylight savings time; sigh!) would be 0.62 in DIT, and so would Babylonian 13:30 in the UK or 8:30 in Boston, Mass. This may look like a trivial simplification, but makes a universe of a difference in how much less painful time calculations become.
I admit I'd much rather have based time keeping on the second (the SI unit of time), but I have to give Anarkat that the day is much more important in most people's lives than the second. Thus, their plan obviously is a lot saner for human use than any I would have come up with (“let's call the kilosecond kes and use that instead of an hour…”)[1].
If you use pelican…
Since I think that this would be a noticeably better world if we adopted DIT (clearly, in a grassrootsy step-by-step process), I'd like to do a bit of propaganda for it. Well, a tiny bit perhaps, but I am now giving the timestamps of the posts on this blog in StarDIT, which is an extension of DIT where you count the days in a (Gregorian, UTC-12) year and number the years from the “Holocene epoch”, which technically means “prepend a one to the Gregorian year number“ (in other words, add 10'000 to “AD”).
Like DIT itself, with sufficient adoption StarDIT would make some people's lives significantly simpler, in this case in particular historians (no year 0 problem any more!). I would like that a lot, too, as all that talk about “Domini” doesn't quite cater to my enlightened tastes.
How do I do produce the starDITs? Well, I first wrote a rather trivial extension for my blog engine, pelican, which adds an attribute starDIT to posts. You will find it as ditdate.py in my pelican plugins repo on codeberg. Activate it by copying the file into your blog's plugins directory and adding "ditdate" to the PLUGINS list in your pelicanconf.py. You can then use the new attribute in your templates. In mine, there is something like:
<a href="http://blog.tfiu.de/mach-mit-bei-dit.html">DIT</a>
<abbr class="StarDIT">{{ article.starDIT[:-4] }}</abbr>
(<abbr class="date">{{ article.date.strftime("%Y-%m-%d") }}</abbr>)
If you don't use pelican…
I have also written a Python module to convert between datetimes and DITs which shows a Tkinter UI when called as a program:
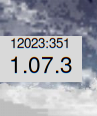
I have that on my desktop now. And since alarmingly many people these days use a web browser as their primary execution platform, I have also written some HTML/Javascript to have the DIT on a web page and its title (also hosted here).
Both of these things are in my dit-py repo on codeberg, available under CC0: Do with them whatever you want. (Almost) anything furthering the the cause of DIT is – or so I think I have argued above – very likely progress overall.
| [1] | If you speak German or trust automatic translation, I have a longer elaboration of DIT aspects I don't like in a previous blogpost. |











