![[RSS]](../theme/image/rss.png)
Neun Monate Umwelt-CO₂, Teil II: Hochpass, Tiefpass, Spektrum
Am Ende des Posts verrate ich, welche Bewandnis es mit diesem hübschen, nachgerade frühlingshaften Muster hat. Und auch, wie mensch sowas selbst macht.
Ich habe letztes Jahr neun Monate lang CO₂-Konzentrationen auf meinem Balkon gemessen, in der Hoffnung, ein wenig hinter die Gründe für die doch überraschend großen Konzentrationsschwankungen zu kommen, für die ich bei einer ersten Messung im November 2021 nur sehr spekulative Erklärungen gefunden habe (Stand Februar vor allem: die lokale Heizung und eventuell das Kraftwerk in Rheinau oder die Chemiefabriken in Ladenburg oder Ludwigshafen). Ich habe dann neulich an der Kalibration der Daten gespielt und bin zum Schluss gekommen, dass sie nach Maßstäben von KonsumentInnenelektronik recht ordentlich sein dürften.
Jetzt möchte ich ein wenig in den Daten rumfummeln. „Explorative Datenanalyse“ nennen das Leute, die das mit dem Fummeln nicht zugeben wollen, und in der ernsthaften Wissenschaft wird zurecht etwas die Nase gerümpft, wenn jemand sowas macht: Es stecken in jedem hinreichend großen Datensatz fast beliebig viele Korrelationen, und wer sie sucht, wird sie auch finden. Leider sind (fast) alle davon Eigenschaften des Datensatzes bzw. der Messung, nicht aber des untersuchten Gegenstands.
Andererseits: Ohne Induktion (was in normale Sprache übersetzt „Rumspielen, bis mensch einen Einfall hat“ heißt) gibt es, da muss ich Karl Popper ganz heftig widersprechen, keine Erkenntnis, und Deduktion kann mensch nachher immer noch machen (also, ich jetzt nicht, weil das hier mein Freizeitvergnügen ist und keine Wissenschaft).
Erstmal glätten
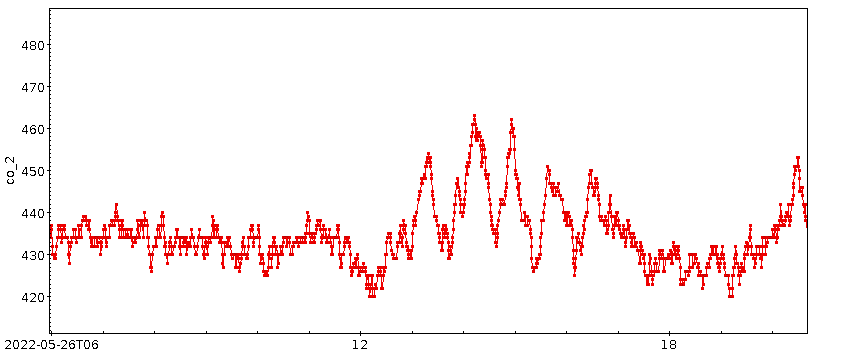
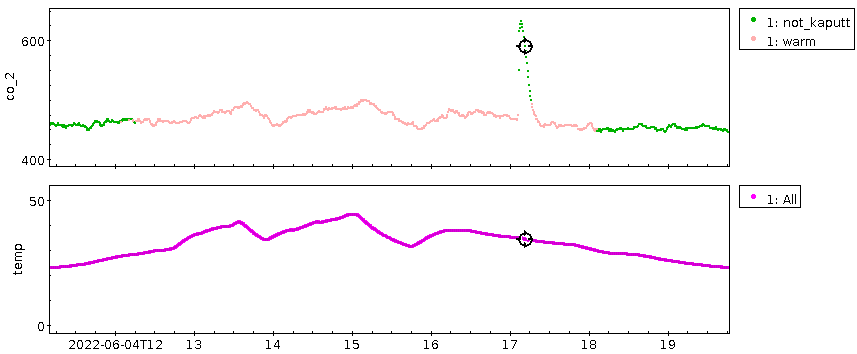
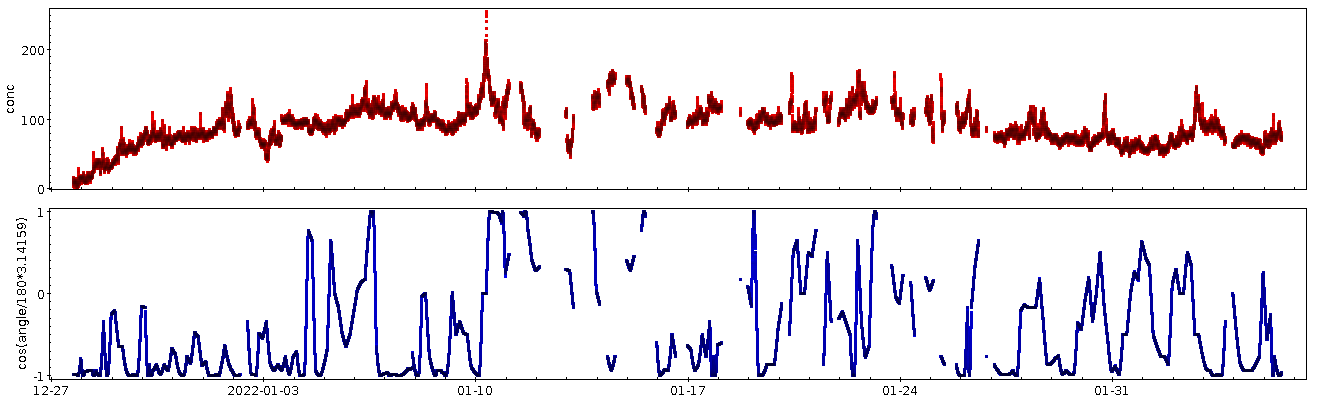
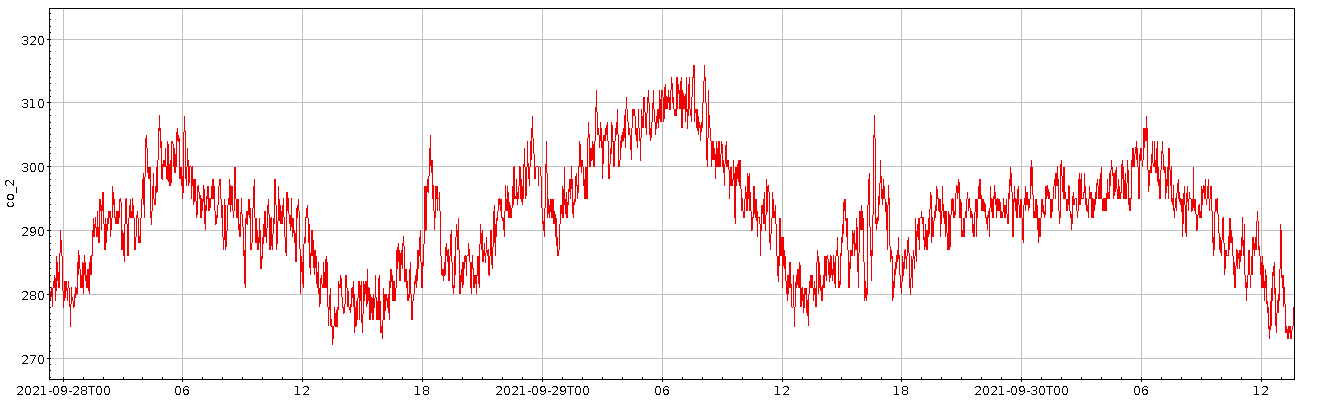
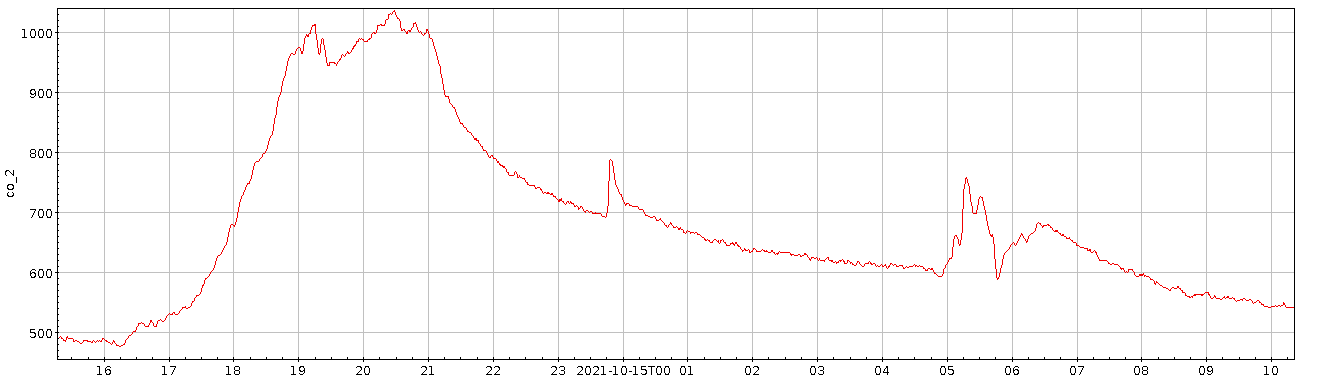
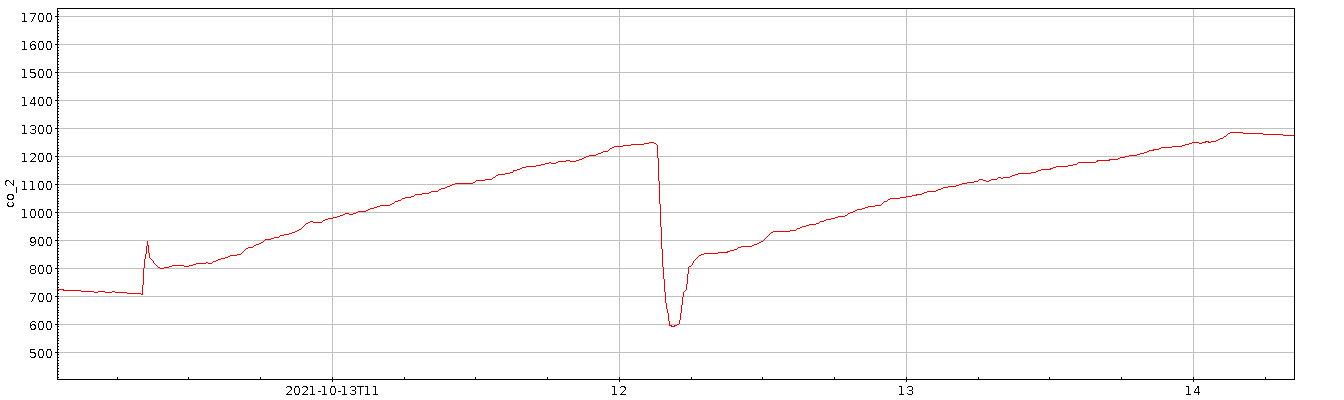
Meine ganz große Enttäuschung mit dem Datensatz war ja, dass sich fast kein Jahreszeiteneffekt gezeigt hat; natürlich werde ich hier, mitten im dichtbesiedelten Oberrheingraben, kein so hübsches Signal bekommen wie die Leute mit der klassischen Messung am Mauna Loa – davon, dass ich eine Schwingung von ein paar ppm nachvollziehen könnte, ganz zu schweigen. Aber ich hatte im September 2021 unter 300 ppm gemessen, während es im Herbst auf die global eher aktuellen 400 bis 500 ppm hochging. Ich hatte gehofft, den Weg zurück zu den 300 ppm im Laufe des Sommers beobachten zu können. Doch leider ist in den (Roh-) Daten erstmal nur Gekrakel:

Wenn in einem Datensatz nur Gekrakel ist, es aber einen langfristigen Effekt geben soll, hilft oft Glätten. Dabei ersetzt mensch jeden Punkt durch einen geeignet gebildeten Mittelwert über eine größere Umgebung dieses Punktes, wodurch kurzfristiges Gewackel wie in meinen Rohdaten stark unterdrückt wird und die langfristigen Trends besser sichtbar werden sollte. Es gibt noch einen zweiten Gewinn: Mensch kann das so gewonnene Mittel von den Daten abziehen und hat sozusagen destilliertes Gewackel (den „hochfrequenten Anteil“), der auf diese Weise auch ein klareres Signal zeigen mag.
Im einfachsten Fall lässt sich so eine Glättung in ein paar Zeilen Python schreiben, und das auch noch relativ effizient als gleitendes Mittel unter Verwendung einer zweiendigen Queue aus Pythons großartigem Collections-Modul: Um das Mittel zu berechnen, addiere ich auf einen Akkumulator, und das, was ich da addiere, muss ich wieder abziehen, wenn der entsprechende Wert aus dem Fenster rausläuft. Dazu gibts noch die Subtilität, dass ich Zeit und Konzentration in der Mitte des Fensters zurückgeben will. Das führt auf so eine Funktion:
def iter_naively_smoothed(in_file, smooth_over):
queue = collections.deque()
accum = 0
for time, co2 in iter_co2(in_file):
queue.append((time, co2))
accum += co2
while time-queue[0][0]>smooth_over:
_, old = queue.popleft()
accum -= old
time, base_co2 = queue[len(queue)//2]
yield time, accum/len(queue), base_co2-accum/len(queue)
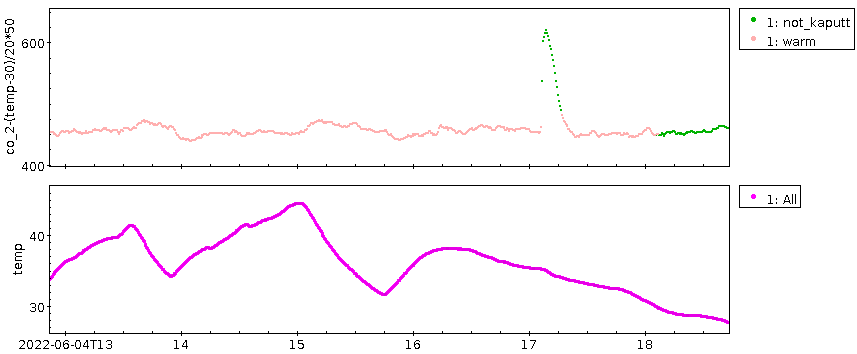
Als Plot sehen die über drei Tage[1] geglättete Konzentrationskurve und die Residuen so aus:
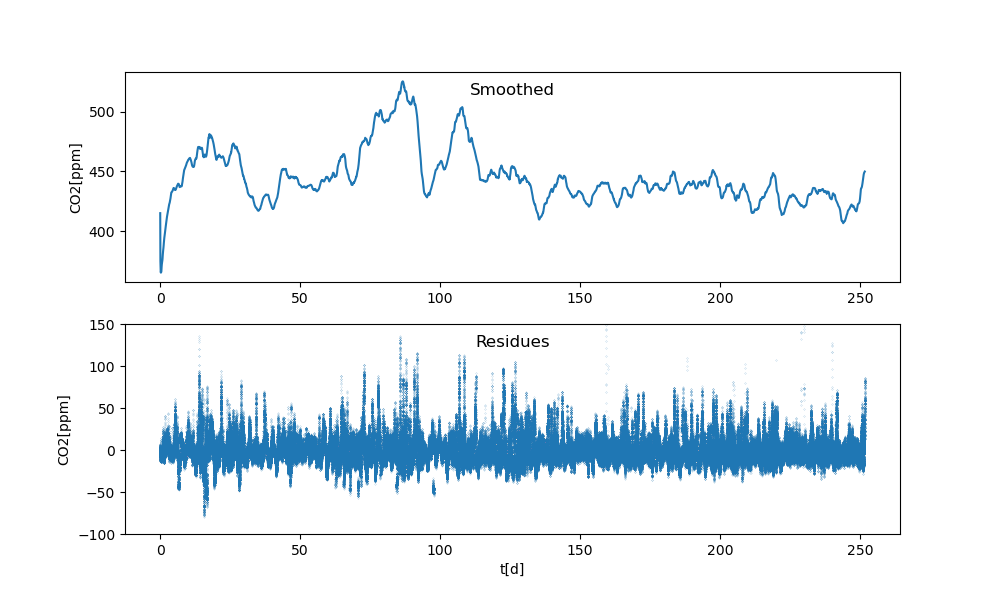
Die Ränder, vor allem der linke, sind dabei mit Vorsicht zu genießen, da dort fast nichts geglättet ist; die Funktion ist so geschrieben, dass dort die Fenster klein sind. So oder so: auch die geglättete Kurve hat keine nennenswerte Tendenz. Allenfalls die beiden großen Ausschläge bei den Tagen 80 und 110 könnten ein Signal sein.
Zeitrechnungen
„Tag 80” ist jetzt keine wirklich intuitive Angabe, aber ich wollte in den Plots nicht mit läsitgen Kalenderdaten operieren. Für die Interpretation wären sie jedoch schon ganz gut. Wie komme ich von Messtag auf ein bürgerliches Datum?
Die Daten kommen original mit Unix-Timestamps, also der Zahl der Sekunden seit dem 1.1.1970, 0:00 Uhr UTC, und sie fangen mit 1640612194 an. Um ausgehend davon bürgerliche Daten auszurechnen, muss mensch wissen, dass ein Tag 86400 Sekunden hat. Pythons datetime-Modul liefert dann:
>>> import datetime >>> datetime.datetime.fromtimestamp(1640612194+80*86400) datetime.datetime(2022, 3, 17, 14, 36, 34) >>> datetime.datetime.fromtimestamp(1640612194+110*86400) datetime.datetime(2022, 4, 16, 15, 36, 34)
Mitte März und Mitte April ist also möglicherweise was Interessantes passiert. Da gucke ich nochmal drauf, wenn ich demnächst Wetterdaten einbeziehe.
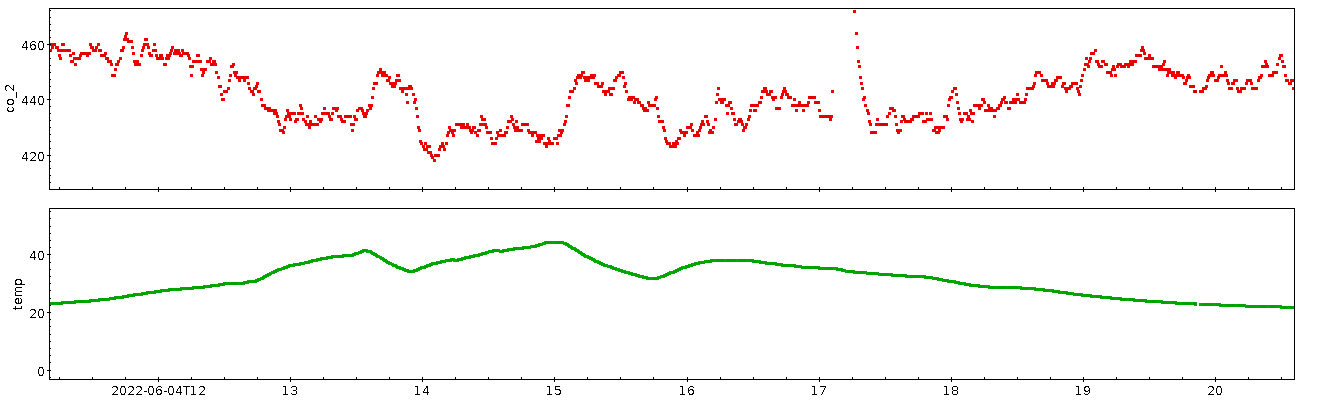
Die andere Seite, die Residuen, kann ich für eine saubere Fassung des Tagesplots aus Teil 1 verwenden. Weil längerfristige Schwankungen bei ihnen rausgerechnet sind, sollte ein regelmäßiger Tagesgang in den Residuen deutlicher herauskommen als im ganzen Signal. Dazu nehme ich wieder den Rest bei der Division durch 86400 (siehe oben), und die Warnungen wegen Zeitzonen aus dem Kalibrationspost gelten immer noch.
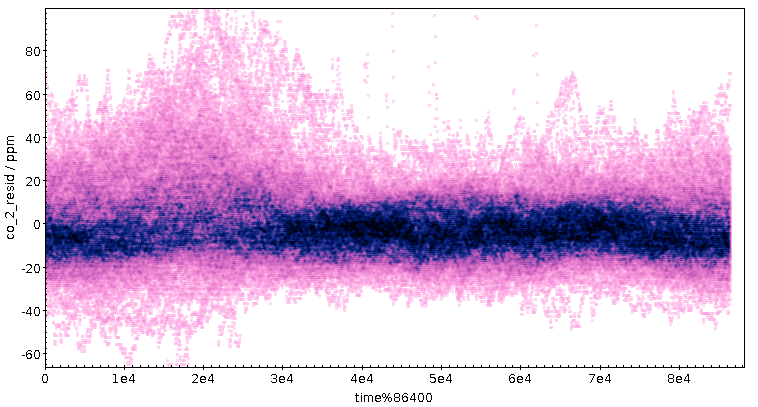
Dass da „am Morgen” (15000 Sekunden sind etwa 4:15 Uhr UTC, also 5:15 MEZ und 6:15 MESZ) irgendwas passiert, dürfte ein robustes Signal sein, und es kommt ohne die niederfrequenten Signale deutlich besser raus. Mit etwas Wohlwollen könnte mensch vielleicht sogar zwei Berge im Abstand von einer Stunde sehen, was dann Normal- und Sommerzeit entspräche. Da der Sensor nicht weit von der Bundesstraße 3 stand, liegt als Erklärung zunächst Berufs- und Pendelverkehr nahe.
Wenn der Tagesgang tatsächlich mit dem Berufsverkehr am Morgen zu tun hat, müsste sich eigentlich ein Signal im Wochenrhythmus zeigen, denn zumindest Sonntags ist es hier am Morgen deutlich ruhiger als an Werktagen. Die Projektion auf die Woche ist einfach: Statt den Rest bei der Division durch 86'400 nehme ich jetzt den Rest bei der Division durch 604'800, die Zahl der Sekunden in einer Woche. Das Ergebnis zeigt, vielleicht etwas überraschend, das Tagessignal eher deutlicher; ein Wochensignal hingegen ist weniger überzeugend erkennbar:
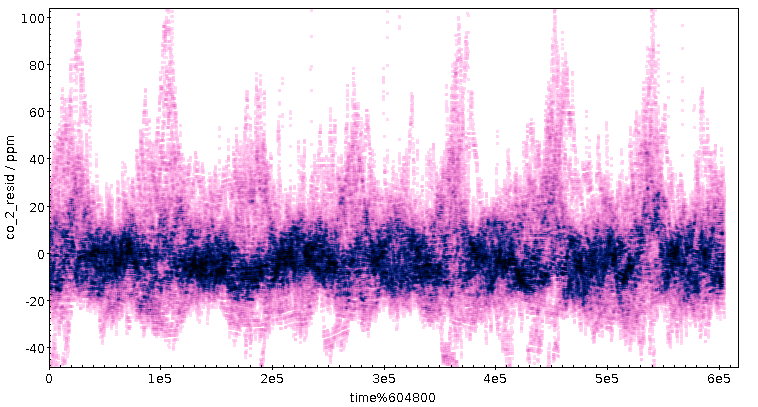
Vielleicht ist an den Tagen drei und vier etwas weniger los – welche Wochentage sind das? Nun, ich dividiere hier Unix-Timestamps; ihr erinnert euch: Die Sekunden seit dem 1.1.1970. Welcher Wochentag war dieser 1.1.?
$ cal 1 1970
January 1970
Su Mo Tu We Th Fr Sa
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30 31
Weil die Unix-Epoche so eine große Rolle im heutigen Leben spielt[2], nehme das mal als erweiterte Kopfzahl: Er war ein Donnerstag. Und so sind die Tage 3 und 4 tatsächlich Samstag und Sonntag. Meine Autoabgas-These ist mir durch diese Prüfung etwas sympathischer geworden. Vermutlich fallen die Abgase nur bei wenig Wind und wenig Thermik (das ist praktisch die berüchtigte Dunkelflaute…) auf, so dass das dunkle Band mit hoher Punktdichte mehr oder minder bei der Null bleibt, jedoch immer wieder Spitzen mit bis zu 100 ppm extra in der Rush Hour auftreten. Wenn das hier Wissenschaft wäre, müsste ich mich jetzt auf die Suche nach Daten aus der Verkehrszählung machen.
Und ich müsste überlegen, ob die Zacken im dunklen Band nicht doch ein echtes Signal sind. Speziell der Durchhänger so um die 180'000 Sekunden (also in der Nacht von Freitag auf Samstag) ist eigentlich kaum wegzudiskutieren. Aber was könnte gerade da plausiblerweise mehr frische Luft heranführen? Oder ist das, weil die Freitagnacht wegen Spätcorona noch besonders ruhig war?
In Sachen Spitzen am Morgen hätte ich eine Alternativhypothese zu den Autoabgasen: Das könnte nämlich wieder der lokale Brenner sein. Dann wäre das, was da zu sehen ist, die Warmwasserbereitung zur Morgendusche. Attraktiv ist diese These schon allein, weil mir 6:15 eigentlich ein wenig früh vorkommt für das Einsetzen der Rush Hour nach Heidelberg rein; es ist ja nicht so, als seien da noch viele nennenswerte Industriebetriebe, in denen die Leute um sieben stechen müssten. Allerdings: in einem Wohnblock mit so vielen Studis wie meinem hier ist 6:15 auch keine plausible Zeit für massenhaftes Duschen…
Spektralanalyse
Was ich gerade gemacht habe, ist ein Spezialfall einer gerade für uns AstrophysikerInnen extrem wichtigen Technik – ich habe nämlich ein Signal nach Frequenzen aufgeteilt. Bis hierher hatte ich nur in zwei Bänder, ein hohes und ein tiefes. Mit der Fourieranalyse geht das viel allgemeiner: Mensch steckt ein Signal rein und bekommt ein Spektrum heraus, eine Kurve, die für jede Frequenz sagt, wie stark Schwingungen auf dieser Frequenz zum Signal beitragen.
Mit dem Universal-Werkzeugkasten scipy kriegt mensch so ein Spektrum in anderthalb Zeilen Python:
from scipy import signal f, power = signal.periodogram(samples[:,1], fs=86400/24/120)
Dabei übergebe ich nur meine Konzentrationsmessungen, nicht die zugehörigen Zeiten, weil die periodogram-Funktion nur mit gleichmäßig gesampleten Daten zurechtkommt. Das sind meine Daten zum Glück: zwischen zwei Messungen liegen immer 30 Sekunden, und es sind auch keine Lücken in den Daten.
Die halbe Minute Abstand zwischen zwei Punkten übergebe ich im Argument fs, allerdings als Frequenz (der Kehrwert der Periode) und umgerechnet in die Einheit „pro …









{kind=link}
{kind=link}