![[RSS]](./theme/image/rss.png)
Zu den unerfreulicheren Begleiterscheinungen der Coronapandemie gehörte die vielstimmige und lautstarke Forderung nach „mehr Daten“, selbst aus Kreisen, die es eigentlich besser wissen[1]. Wie und warum diese Forderung gleich mehrfach falsch ist, illustriert schön ein Graph, der seit ein paar Wochen im RKI-Wochenbericht auftaucht:
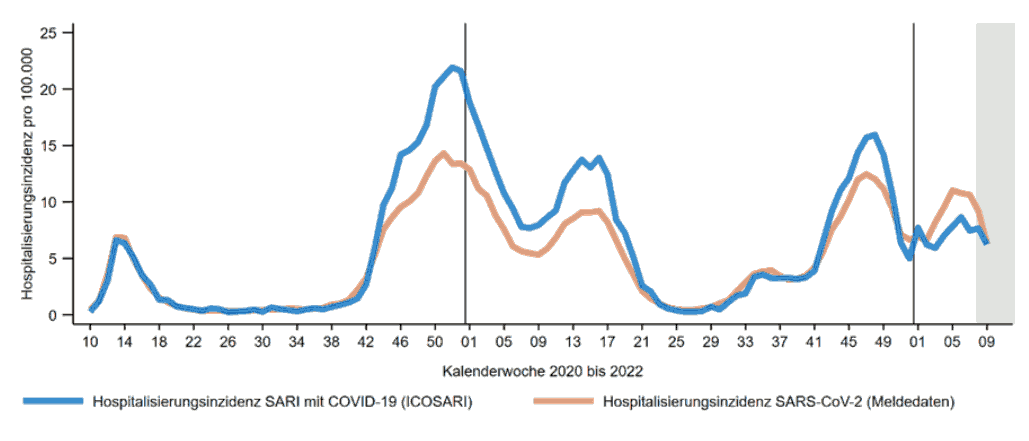
Quelle: Wochenbericht vom 10.3.2022. Rechte beim RKI.
Dargestellt sind die Zahlen von „im Zusammenhang mit“ SARS-2 in deutsche Krankenhäuser aufgenommenen PatientInnen. Die orange Kurve entspricht dabei den „Big Data“-Zahlen aus der versuchten Totalerfassung – d.h., Krankenhäuser melden einfach, wie viele Menschen bei der Aufnahme SARS-2-positiv waren (oder vielleicht auch etwas anderes, wenn sie das anders verstanden haben oder es nicht hinkriegen). Die blaue Kurve hingegen kommt aus der ICOSARI-Surveillance, also aus spezifischen Meldungen über Behandlungen akuter Atemwegsinfektionen aus 71 Kliniken, die für Meldung und Diagnose qualifiziert wurden.
Wären beide Systeme perfekt, müssten die Kurven im Rahmen der jeweiligen Fehlerbalken (die das RKI leider nicht mitliefert; natürlich zählt keines von beiden ganz genau) übereinanderlaufen. Es ist offensichtlich, dass dies gerade dann nicht der Fall ist, wenn es darauf ankommt, nämlich während der Ausbrüche.
Eher noch schlimmer ist, dass die Abweichungen systematisch sind – die Entsprechung zu halbwegs vertrauten Messungen wäre, wenn mensch mit einem Meterstab messen würde, dessen Länge eben nicht ein Meter ist, sondern vielleicht 1.50 m. Nochmal schlimmer: seine Länge ändert sich im Laufe der Zeit, und auch abhängig davon, ob mensch Häuser oder Giraffen vermisst. Wäre der Meterstab wenigstens konstant falsch lang, könnte mensch die Messergebnisse im Nachhinein jedenfalls in gewissem Umfang reparieren („die Systematik entfernen“). Bei der Hospitalisierung jedoch wird keine plausible Methode die Kurven zur Deckung bringen.
Das RKI schreibt dazu:
Im Vergleich zum Meldesystem wurden hierbei in den Hochinzidenzphasen - wie der zweiten, dritten und vierten COVID-19-Welle - höhere Werte ermittelt. In der aktuellen fünften Welle übersteigt die Hospitalisierungsinzidenz der Meldedaten die COVID- SARI-Hospitalisierungsinzidenz, weil zunehmend auch Fälle an das RKI übermittelt werden, bei denen die SARS-CoV-2-Infektionen nicht ursächlich für die Krankenhauseinweisung ist.
Die Frage ist nun: Welche Kurve „stimmt“, gibt also das bessere Bild der tatsächlichen Gefährdungssituation für das Gesundheitssystem und die Bevölkerung?
Meine feste Überzeugung ist, dass die blaue Kurve weit besser geeignet ist für diese Zwecke, und zwar weil es beim Messen und Schätzen keinen Ersatz für Erfahrung, Sachkenntnis und Motivation gibt. In der Vollerfassung stecken jede Menge Unwägbarkeiten. Um ein paar zu nennen:
- Wie gut sind die Eingangstests?
- Wie konsequent werden sie durchgeführt?
- Wie viele Testergebnisse gehen in der Hektik des Notfallbetriebs verloren?
- Wie viele Fehlbedienungen der Erfassungssysteme gibt es?
- Haben die Zuständigen vor Ort die Doku gelesen und überhaupt verstanden, was sie erfassen sollen und was nicht?
- Wie viele Doppelmeldungen gibt es, etwa bei Verlegungen – und wie oft unterbleibt die Meldung ganz, weil das verlegende Krankenhaus meint, das Zielkrankenhaus würde melden und umgekehrt?
Und ich fange hier noch gar nicht mit Fragen von Sabotage und Ausweichen an. In diesem speziellen Fall – in dem die Erfassten bei der Aufnahme normalerweise nicht viel tun können – wird beides vermutlich eher unwichtig sein. Bei Datensammelprojekten, die mehr Kooperation der Verdateten erfordern, können die Auswahleffekte hingegen durchaus auch andere Fehler dominieren.
Erfasst mensch demgegenüber Daten an wenigen Stellen, die sich ihrer Verantwortung zudem bewusst sind und in denen es jahrelange Erfahrung mit dem Meldesystem gibt, sind diese Probleme schon von vorneherein kleiner. Vor allem aber lassen sie sich statistisch untersuchen. Damit hat ein statistisch wohldefiniertes Sample – anders als Vollerfassungen in der realen Welt – tendenziell über die Jahre abnehmende Systematiken. Jedenfalls, solange der Kram nicht alle paar Jahre „regelauncht“ wird, was in der heutigen Wissenschaftslandschaft eingestandenermaßen zunehmend Seltenheitswert hat.
Wenn also wieder wer jammert, er/sie brauche mehr Daten und es dabei um Menschen geht, fragt immer erstmal: Wozu? Und würde es nicht viel mehr helfen, besser definierte Daten zu haben statt mehr Daten? Nichts anderes ist die klassische Datenschutzprüfung:
- Was ist dein Zweck?
- Taugen die Daten, die du haben willst, überhaupt dafür? („Eignung“)
- Ginge es nicht auch mit weniger tiefen Eingriffen? („Notwendigkeit“)
- Und ist dein Zweck wirklich so großartig, dass er die Eingriffe, die dann noch übrig bleiben, rechtfertigt? („Angemessenheit“)
Ich muss nach dieser Überlegung einfach mal als steile Thesen formulieren: Datenschutz macht bessere Wissenschaft.
Nachtrag (2022-05-16)
Ein weiteres schönes Beispiel für die Vergeblichkeit von Vollerfassungen ergab sich wiederum bei Coronazahlen Mitte Mai 2022. In dieser Zeit (z.B. RKI-Bericht von heute) sticht der bis dahin weitgehend unauffällige Rhein-Hunsrück-Kreis mit Inzidenzen um die 2000 heraus, rund das Doppelte gegenüber dem Nächstplatzierten. Ist dort ein besonders fieser Virusstamm? Gab es große Gottesdienste? Ein Chortreffen gar? Weit gefehlt. Das Gesundheitsamt hat nur retrospektiv Fälle aus den vergangenen Monaten aufgearbeitet und ans RKI gemeldet. Dadurch tauchen all die längst Genesenen jetzt in der Inzidenz auf – als sie wirklich krank waren, war die Inzidenz zu niedrig „gemessen“, und jetzt halt zu hoch.
So wurden übrigens schon die ganze Zeit die Inzidenzen berechnet: Meldungen, nicht Infektionen. Das geht in dieser Kadenz auch nicht viel anders, denn bei den allermeisten Fällen sind die Infektionsdaten anfänglich unbekannt (und bei richtig vielen bleibt das auch so). Wieder wären weniger, aber dafür sorgfältig und kenntnisreich gewonnene Zahlen (ich sag mal: PCR über Abwässern), hilfreicher gewesen als vollerfassende Big Data.
| [1] | Vom Totalausfall der Vernunft etwa bei der Luca-App will ich gar nicht anfangen. Der verlinkte Rant von Fefe spricht mir ganz aus der Seele. |
Nachtrag (2023-02-08): Das sehe übrigens nicht nur ich so.
Zitiert in: Pelztiere vs. Menschen: Die letzten 70 Jahre Schrödingers Tiger (Un)verstandene Infektionsdynamik Angst ist eine schlechte Beifahrerin Affen zählen ist schwer