![[RSS]](./theme/image/rss.png)
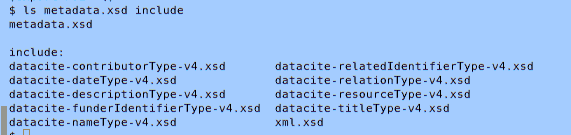
Please don't do it like this: for users of a schema, having to pull it in a dozen fragments is just pain and no gain. See below for a program that lets you heal this particular disease.
While I'm a big fan of XML – which is governed by a very well-written standard and is (DTDs aside) about as easy to process as something context-free can be –, I have always been a lot more skeptical about XML Schema, which is horrendously complex, has a few nasty misfeatures[1] and generally has had a major role in giving XML a bad name.
But well, it's there, and it won't go away. That ought to be reason enough to not encumber it with further and totally avoidable pain. As, for instance, splitting up a single schema into fragments of a couple of lines and then using xs:include liberally to re-assemble the fragments at the client side. Datacite, I'm looking at you. Regrettably, they're not the only ones doing that. And as opposed to splitting a domain mapping into different schemas – which might improve re-usability, this lexical splitting really helps nobody except perhaps the authors.
The use of xs:include is a pain in particular when one tries to implement redistributable validators, as these then need to keep a lot of files in a defined hierarchy. Just pointing to the vendor's site is not an option, because the software would hit that every time it validates something, which is, if nothing else, a privacy and stability problem.
Well, today I had another case of XSD splititis, and this time it was bad enough that I decided to merge the fragments. I had expected people had written “inliners” expanding xs:include in XSDs into standalone XSDs. After all, it's basically a lexical thing (well, excepting namespace mappings and perhaps re-indentation). Five minutes of operating a search engine didn't bring up anything, though, and so I wrote a quick cure: expand-xsd-include.py.
I'll be the first to admit that it is a hack at this point, mainly because I blindly discard the root tags for the included documents. That's wrong because these might add or, worse, change the mapping from prefixes to XML namespaces. In its current state, this will fail badly if included documents use different or extra mappings and declare them in the root element; declarations further down are ok.
Another problem resulting from keeping namespace processing off on the parser is that I hardcode the prefix for the XSD schema to xs. If your schema uses something else, change XSD_PREFIX in the script.
Mending these deficiencies wouldn't be an undue effort, and if you have XSDs that need it, let me know and I'll do proper namespace processing. Or perhaps, in addition, teach the thing to pull the input files via http. Meanwhile, I suspect that the large majority of atomised XSDs can be merged with this code, and so I thought I might as well put it online in its slightly embarrassing shape.
Let me know if you use it. And if you distribute fragmented XSDs: Why not use the script to assemble your XSD before publishing it?
| [1] | The worst XSD misfeature IMHO are the namespaced attribute values; where XML has been designed to be parsable without external DTDs (ok, not generally, but under well-defined conditions, and it's been a long time since I saw a document that didn't meet those), parsing results with namespaced attribute values depend on whether or not the parser knows the XSD. And that would even be bad without the ugly schemaLocation hacks in both schema and schema instance. |