![[RSS]](./theme/image/rss.png)
Jede vierte Stimme nicht im Parlament vertreten
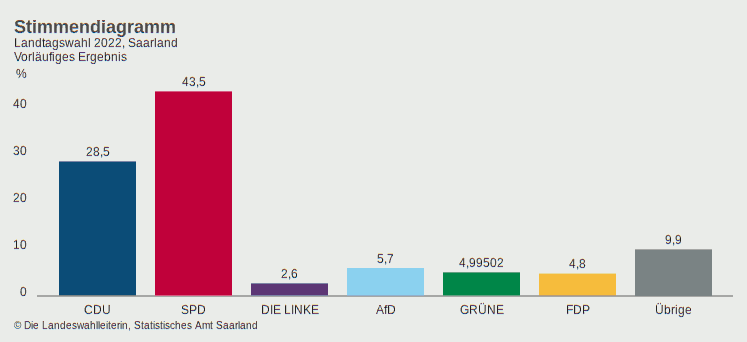
Stimmenanteile der verschiedenen Listen bei der Wahl im Saarland gestern. Wahlbeteiligung: 61.4%. Rechte beim Saarland.
Mensch muss meine informationstheoretischen Bedenken vom letzten Oktober im Hinblick auf die repräsentative Demokratie nicht teilen, um die 5%-Hürde wirklich befremdlich zu finden: Warum genau sollten „Minderheiten“, denen deutlich mehr als jedeR zwanzigste StaatsbürgerIn angehören kann[1], nicht im Parlament vertreten sein?
Dies ist eine sehr ernste Frage, wenn wer „die Bevölkerung“ im Parlament „abgebildet“ sehen will. Hinter diesem Bild von der Abbildung steht die (sicher zutreffende) Prämisse, dass da eben nicht ein „Volk“ einen Willen hätte und per Wahl eine Art kollektive Sprecherin gefunden hätte. Nein, dieses Bild erkennt an, dass die Regierten ein mehr oder minder buntes Häufchen Leute sind, die sich über allerlei Fragen ziemlich uneins sind. Sollen zumindest die wesentlichsten ihrer Perspektiven im Parlament reflektiert sein (an der Stelle kommt übrigens der Einspruch der Informationstheorie, denn es wird sicherlich mehr als 20 relevantere Perspektiven geben), fällt mir wirklich keine plausible Begründung mehr ein, warum eine Initiative, zu der sich schon mal fünf von hundert Menschen verabreden können, nicht nur nicht an Regierung beteiligt sein, sondern nicht mal eine Stimme im Parlament haben soll.
26% der Bevölkerung machen die absolute Mehrheit im Parlament.
Ein weiterer Seiteneffekt der 5%-Hürde hat gestern im Saarland besonders zugeschlagen. Wer nämlich die Stimmen aller von ihr aus dem Parlament gekickten Parteien zusammenzählt, kommt auf 23% (es sei denn, die Grünen rutschen doch noch rein). Wie in der Überschrift gesagt: Fast jede vierte Stimme ist damit nicht im Parlament vertreten. Das ist mehr als die Hälfte des Stimmenanteils der SPD (26% der Bevölkerung, 43.5% der abgegebenen Stimmen) und damit einer (unter diesen Umständen) sehr komfortablen absoluten Mehrheit. Dieses Viertel der WählerInnen sehen die, von denen sie sich vertreten lassen wollten – die z.B. für sie Parlamentsanfragen hätten stellen können – nicht im Parlament.
Das ist bitter, denn bei aller Kritik an der Sorte Parlamentarismus, bei der die Exekutive bei Strafe ihres Untergangs die Legislative immer an der kurzen Kandare halten muss, sind gerade die Mittel der Opposition – die Anfragen ganz besonders – ein wichtiges Mittel politischer Einflussnahme. Hier in Baden-Württemberg z.B. fehlt die Linke im Landtag schon, weil auf diese Weise bis heute unklar ist, welche Bomben und Panzerfäuste die Polizei gekauft (und gar eingesetzt?) hat, nachdem ihr das die vorletzte Verschärfung des Polizeigesetzes erlaubt hat; die SPD, die die Verschärfung damals mit den Grünen zu verantworten hatte, geriert sich in dieser Angelenheit immer noch auffallend exekutiv.
Zum praktischen Ärger tritt, dass selbst bei der – eigentlich im Sinne der Partizipation ausgegangenen – letzten Prüfung von Sperrklausen vor dem Bundesverfassungsgericht (2BvE 2/13 u.a., 2014-02-26) in der Urteilsbegründung noch die reaktionäre Klamotte durchschien, die Parteienvielfalt in der Weimarer Republik habe den Faschismus ermöglicht. In Randnummer 54 schreibt das Gericht verklausulierend:
Eine große Zahl kleiner Parteien und Wählervereinigungen in einer Volksvertretung kann zu ernsthaften Beeinträchtigungen ihrer Handlungsfähigkeit führen.
Die darunterliegende Erzählung war schon bei der Einführung der 5%-Hürde in den 1950er Jahren eine ebenso abwegige Schutzbehauptung wie entsprechende Behauptungen zur Inflation: Wer das Paktieren des SPD-Reichspräsidenten mit den reaktionärsten Elementen einer ohnehin in weiten Bereichen noch vormodernen Gesellschaft bereits in der Gründungsphase des Staates ansieht, wird sich eher fragen, wie es die halbwegs liberalen Institutionen überhaupt bis zur Machtübergabe 1933 geschafft haben.
Weniger und besser regieren ohne die 5%-Hürde.
Klar dürfte „das Regieren“ etwas mühsamer werden, wenn die Bevölkerung im Parlament feinkörniger vertreten ist. Aber die ganze Geschichte mit Demokratie und Volkssouveränität wurde auch nicht gemacht, damit es eine konkrete Regierung einfacher hat. Entstanden ist sie als Reaktion auf Rabatz, der wiederum Folge war von regelmäßig katastrophalem Agieren von Regierungen, die autoritären Versuchungen zu sehr nachgegeben haben.
Dass mehr Partizipation (oder, wenn ihr wollt, Demokratie) es Regierungen schwerer macht, über Einwände signifikanter Teile der Regierten hinwegzuregieren: das ist kein Bug, das ist ein Feature. Und wenn ihr mal darüber nachdenkt, was z.B. die Bundesregierungen der letzten 20 Jahre so beschlossen haben – mal angenommen, es wären nur die 10% konsensfähigsten Gesetze durchgekommen: Wäre das nicht eine viel bessere Welt?
Immerhin öffnet das oben zitierte Karlsruher Urteil die Tür für Verbesserungen recht weit, wenn es in RN 57 heißt:
Eine einmal als zulässig angesehene Sperrklausel darf daher nicht als für alle Zeiten verfassungsrechtlich unbedenklich eingeschätzt werden. Eine abweichende verfassungsrechtliche Beurteilung kann sich ergeben, wenn sich die Verhältnisse wesentlich ändern. Findet der Wahlgesetzgeber in diesem Sinne veränderte Umstände vor, so muss er ihnen Rechnung tragen.
Zum Abschluss doch nochmal Informationstheorie: die 5%-Hürde beschränkt ja die Zahl der maximal im Parlament vertretenen Parteien auf 20 (und das auch nur theoretisch, denn die Bevölkerung müsste schon extrem gut geplant abstimmen, um jeder Partei gerade genau 5% der Stimmen zukommen zu lassen). Der Zweierlogarithmus von 20 ist 4.322. Zu deutsch: Mit der Hürde ist der Informationsgehalt der Wahlentscheidung hart auf gut 4 bit gedeckelt. Aua.
| [1] | Bei 100% Wahlbeteiligung und universellem Wahlrecht sind 5% ein Mensch von 20. Bei 60% Wahlbeteiligung wie im Saarland und gleichmäßiger Wahlausübung wären es eineR von 12, der/die nach der 5%-Logik vernachlässigbar wäre. Da die Wahlausübung stark mit der Zugehörigkeit zu Interessengruppen (z.B. bei Kindern: 0% Wahlbeteiligung…) korreliert, können aber noch weit größere Teile der Bevölkerung durch die 5%-Hürde ausgeschlossen sein. |















{kind=link}
{kind=link}
{kind=link}