Als Reaktion auf meinen Hilferuf gegen Google hat
@ulif@chaos.social getrötet:
Vielleicht einfach mal unverbindlich bei der irischen
"Datenschutzbehörde" nachfragen? Nicht als Beschwerde, sondern als
einfache Anfrage. Denen müssen sie diese Daten ja eigentlich gemeldet
haben.
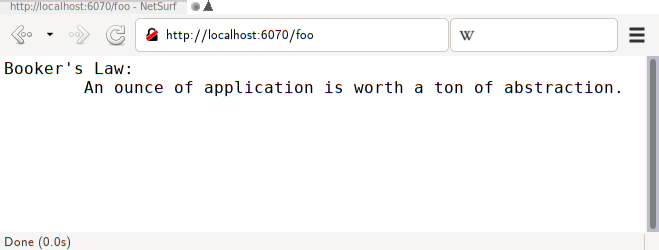
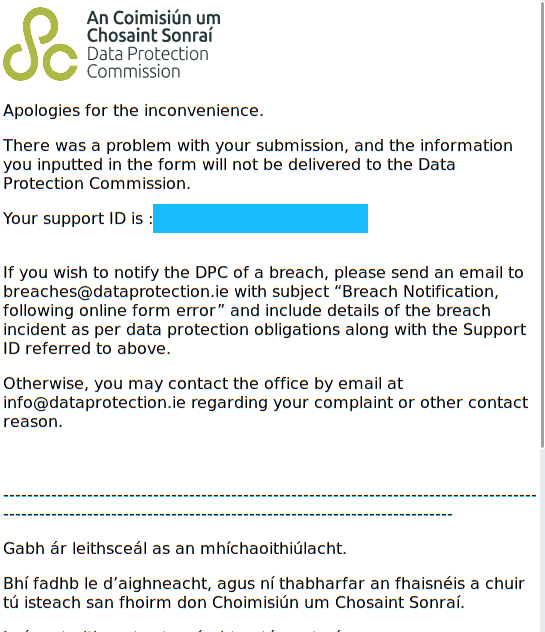
Na schön. Das könnte interessant werden. Das erste Ergebnis einer
duckduckgo-Anfrage nach „data protection ireland“. führt gleich zur
data protection commission (bzw. Choimisiún um Chosaint Sonraí),
https://www.dataprotection.ie/, und ich bekomme beim Draufklicken
original das hier:
Keine GET-Parameter, kein POST-Payload, einfach nur
https://www.dataprotection.ie/, und schon habe ich eine support ID. Oh
wow. Interessanterweise ändert sich das auch nicht, wenn ich
dataprotection.ie Javascript erlaube; mit einem Firefox (statt einem
luakit) erscheint hingegen die Webseite, wie sich die Leute das wohl
vorgestellt haben.
Wie kommt das? Ich curl-e mal eben die Seite und sehe schon recht weit
oben:
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@dpcireland" />
<meta name="twitter:title" content="Homepage | Data Protection Commission" />
und noch ein paar mehr Zeilen Twitter-Service. Diese Leute sollten
dringend mal ihrem Kollegen in Baden-Württemberg zuhören.
Immerhin kommen aber keine Webfonts von Google, und es laufen auf den
ersten Blick auch keine externen Tracking-Dienste („Analytics“). Aber
ich finde kein Refresh-Meta oder etwas anderes, das erklären könnte,
warum luakit diese eigenartige Fehlermeldung ausgeliefert bekommen
könnte, während an curl und firefox recht anständige Antworten gehen.
Leider macht auch dataprotection.ie die bedauerlichen
Zwangs-Redirects auf https, so dass es nicht ganz einfach ist,
zuzusehen, was mein Browser und der Webserver der IrInnen eigentlich
miteinander ausmachen. Aber ich bin neugierig genug auf das,
was da zwischen meinem Browser und dem dataprotection.ie-Server vorgeht,
dass ich meinen mitmproxy auspacke und damit in die Kommunikation
meines eigenen Computers einbreche.
Auf diese Weise sehe ich meinen Request:
GET https://www.dataprotection.ie/
Host: www.dataprotection.ie
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Tracking is lame.
Accept-Encoding: gzip, deflate
Accept-Language: C
Connection: Keep-Alive
Ah… richtig… ich bin ein wenig gemein mit der Sprach-Aushandlung in
meinem normalen Browser und frage die Webseiten nach der Sprache C (was
weniger gemein ist als es scheinen mag, aber das ist ein längeres Thema).
Ein schnelles Experiment bestätitgt, dass es das ist, was den Drupal
(das ist das Programm, das deren Webseite macht) der irischen
Datenschutzbehörde getötet hat.
Wenn das noch oder wieder kaputt ist, wenn du das hier liest,
ist eine einfache Kommandozeile, um das Problem zu reproduzieren:
$ curl -s -H "Accept-Language: C" https://www.dataprotection.ie/ | head -5
<!DOCTYPE html>
<html lang="en">
<head>
<title> Website error notice | Data Protection Commission </title>
</head>
Aber egal, ich war ja eigentlich nicht hier, um Webseiten zu debuggen.
Wichtig ist: Ich habe eine Mailadresse. Und das ist viel besser als
das, was auf der normalen Webseite steht:
Echt jetzt? Papierpost ist ja schon noch sowas wie ein offener
Standard, aber dann nur die proprietären, überwachungskapitalistischen
Dienste Twitter, Instagram und Linkedin für Kontaktaufnahme anzubieten
und nicht die offene Mail, das wäre auch für einen normalen Laden schon
ein starkes Stück. Für eine Datenschutzbehörde… Na ja, ok, wir reden
hier über die irische.
Immerhin steht in deren data protection statement:
If you wish to contact our Data Protection Officer in relation to the
processing of your personal data by the Commission, you can do so by
e-mailing dpo@dataprotection.ie.
Schön: immerhin gibts da eine Mailadresse, bei der ich mich beschweren
könnte, aber ganz ehrlich: Anständige DatenschützerInnen sollten da
bitte noch einen PGP-Schlüssel dazuschreiben. Jaja, ich weiß: das hier
sind die irischen…
Ich sollte natürlich nicht so voreingenommen sein; nur weil die bisher
ein Witz waren, heißt das ja nicht, dass sie das auch weiter sein
werden, und so habe ich ihnen gerade eine Mail geschickt:
Dear DPO,
It seems your staff has already fixed it, presumably after I
triggered some sort of alarm system while investigating the problem
(in which case: apologies!), but your CMS until a few minutes ago
produced error messages like the one on
http://blog.tfiu.de/media/2022/ie-data-protection-breakage.png when
queried with an
Accept-Language: C
header. I'm reporting this partly to make sure the apparent fix
wasn't a fluke. If it wasn't: kudos to your operations people to have
noticed and fixed the problem so quickly.
While I'm here, can I also put forward the reason I'm contacting you
in the first place?
You see, I'm trying to get rid of a Google account I created perhaps
15 years ago. To do that, Google tells me to log in. When I try
that, Google asks for the e-mail address associated to the account
(which is <withheld here>), then for the password.
After I've put that in, Google sends a mail to the account with a
confirmation code, which is perhaps not entirely unreasonable given
I've steered clear of Google services requiring authentication for
many years.
But even after entering that confirmation code, it will not let me
in, requiring me to enter a telephone number. This is absolutely
unreasonable, and I would be grateful if you could tell Google that
much; given that Google does not know any telephone number associated
to me, there is no way this information could fend off abuse. This
is clearly a blantant attempt to skim off the extra piece of data.
I would normally not be bothering you with this obvious imposition,
though; I would have liked to first take this to Google's data
protection officer. However, I was unable to locate contact
information in Google's privacy statements (I was served the German
version), which I claim is in open violation of GDPR Article 13.
So, could you
(a) tell Google to publish a proper e-mail contact address as part of
their GDPR information? While I have to admit that the GDPR is not
explicit about it, it is clear to me that Google's own web forms,
in particular when they require Javascript and Captchas, or, even
worse, a google id, are insufficient to fulfil Art 13 1 (b) GDPR.
(b) meanwhile, provide me with the contact e-mail of Google's data
protection officer so I can take my issue to them myself?
Thanks,
(not Anselm Flügel)
Ich bin neugierig, wie es weitergeht. Lobend will ich schon mal
erwähnen, dass der irische DPO offenbar keine automatisierten
Empfangsbestätigungen („Wir werden uns Ihrem Anliegen so bald wie
möglich widmen“) verschickt.
Fortsetzung folgt. Voraussichtlich.
Ich muss das Lob zurücknehmen. Es gab doch eine (halb-)
automatisierte Empfangsbestätigung, abgeschickt um 14:47 Lokalzeit in
Dublin. Für ein Verfahren, das nur auf Computer setzt, ist das eine
komische Zeit bei einer Mail, die am Vorabend um 19:17 MESZ rausging.
Wirklich gelesen hat die Mail aber auch niemand. Das weiß ich schon,
weil sie mich mit „To Whom It May Concern“ anreden, aber auch wegen
der angesichts meiner Anfrage widersinnigen Empfehlung, ich möge mich
doch an den Datenschutzbeauftragten „for that organisation“ wenden.
Weil Leute vielleicht später mal die Evolution des Kundendienstesisch
des irischen DPO nachvollziehen wollen, belästige ich euch mit dem
Volltext:
To Whom It May Concern,
I acknowledge receipt of your e-mail to the Data Protection Commission
(DPC) .
In line with our Customer Service Charter, we aim to reply to the concerns
raised by you within 20 working days, though complex complaints may require
further time for initial assessment. In doing so, we will communicate
clearly, providing you with relevant information or an update regarding
your correspondence.
What can I do to progress my concern?
In the meantime, if your concern relates to processing of your personal
data by an organisation (a “data controller”), or you wish to exercise your
data protection rights (for example, access, erasure, rectification), you
may wish to contact the data protection officer for that organisation in
writing in the first instance. You may wish to forward copies of all
written exchanges with the data controller to the DPC if you remain
dissatisfied with the response you receive from them. You should send this
documentation to info@dataprotection.ie and include the above reference
number.
What if I have already contacted an organisation (“data controller”) about
my concerns?
If you have already exchanged written correspondence with the data
controller, and have not included this information with your initial
contact with the DPC, you should send this documentation to
info@dataprotection.ie quoting the case reference shown above.
What happens when I send the DPC additional correspondence or documents?
Please be advised that the Data Protection Commission does not issue
acknowledgements for each item of follow up or supplementary correspondence
received, but this correspondence will be included on the file reference
above and assessed alongside your initial concern. Once this assessment
has been carried out, a substantive response will be issued to you in due
course.
This acknowledgement, and the reference number above, is confirmation that
we have received your correspondence and that it will receive a response at
the earliest opportunity.
Yours sincerely,
Alexandra X. [und noch ein Nachname]
[Ein paar Footer-Zeilen]
Is le haghaidh an duine nó an eintitis ar …
![[RSS]](./theme/image/rss.png)

















.svg){kind=link}
{kind=link}