In der Mathematik ist eine Metrik eigentlich etwas durchaus
Vernünftiges und Nützliches. In den Händen von MacherInnen und
Marktradikalen ist es eine Form entmündigender Zahlenmagie
geworden. Der Gedanke dort ist, dass Menschen Zahlen selten
widersprechen, selbst wenn offensichtlich ist, dass „Lesekompetenz 3429
plusminus 34“ nicht nur nichts bedeutet; es kann gar nichts bedeuten,
weil „Lesen“, wenn da überhaupt irgendwo Zahlen eine Rolle spielen,
zumindest viele Dimensionen hat. Das auf eine Zahl zu reduzieren, ist
deutlich unsinniger als die Angabe, der Gipfel der Zugspitze sei bei
213.3.
Und dennoch werden überall Politiken und allerlei anderes durch Metriken
rechtfertigt; von der Unsitte, auf Webservern die BenutzerInnen auf alle
möglichen und unmöglichen Arten auszuspähen, um dann nutzlose und
ohnehin ignorierte Metriken zu erzeugen, will ich hier gar nicht
anfangen.
Unter diesem Tag, jedenfalls, ärgere ich mich über Beispiele für den
ganzen Phänomenbereich.
Vor 10 Monaten habe ich den ersten Artikel für dieses Blog geschrieben, und
siehe da: Mit diesem sind es jetzt 100 Posts geworden.
Das wäre ein guter Vorwand für ein paar Statistiken, aber da ich ja
generell ein Feind von Metriken bin, die mensch ohne konkrete
Fragestellung sammelt (das ist ein wenig wie beim statistischen Testen:
Wenn du nicht von vorneherein weißt, worauf du testest, machst du es
falsch), bestätige ich mir nur, dass meine Posts viel länger sind als
ich das eigentlich will. Insgesamt nämlich habe ich nach Zählung von
wc -l auf den Quelldateien fast 93000 Wörter in diesen Artikeln.
Zur Fehlerabschätzung: xapian (vgl. unten) zählt nur 89000.
Die Länge der Artikel ist nach wc-Wörtern so verteilt:
Ich weiß auch nicht recht, warum ich mich nicht kürzer fassen kann.
Oder will. Der überlange Post mit 3244 Wörtern ist übrigens der über
die Konfiguration eines Mailservers – und das ist wieder ein gutes
Beispiel für die Fragwürdigkeit von Metriken, denn erstens hat Englisch
fast keine Komposita und ist von daher im Nachteil beim Wörterzählen und
zweitens ist in dem Artikel ziemlich viel Material, das in Wirklichkeit
Rechner lesen, und das sollte wirklich anders zählen als
natürlichsprachiger Text.
Na gut, und einem Weiteren kann ich nicht widerstehen: Wie viele
verschiedene Wörter („Paradigmata“) kommen da eigentlich vor? Das ist
natürlich auch Mumpitz, denn die Definition, wann zwei Wörter
verschieden sind („die Token verschiedenen Paradigmata angehören“), ist
alles andere als tivial. So würde ich beispielsweise behaupten, dass die
Wörter Worte und Wörter praktisch nichts miteinander zu tun haben,
während im Deuschen z.B. auf, schaute und aufschauen besser alle
zusammen ein einziges Paradigma bilden sollten (zusammen mit allerlei
anderem).
Aber ist ja egal, sind ja nur Metriken, ist also eh Quatsch. Und es
gibt die Daten auch schon, was für die Nutzung von und die Liebe zu
Kennzahlen immer ein Vorteil ist. Ich habe nämlich den xapian-Index über
dem Blog, und mit dem kann ich einfach ein paar Zeilen Python
schreiben:
import xapian
db = xapian.Database("output/.xapian_db")
print(sum(1 for w in db.allterms()))
(Beachtet die elegante Längenbestimmung mit konstantem Speicherbedarf –
db.allterms() ist nämlich ein Iterator).
Damit bekomme ich – ich stemme nach wie vor nicht – 16540 raus. Klar,
diese 16540 für die Zahl der verschiedenen Wörter ist selbst nach den
lockeren Maßstäben von Metriken ganz besonders sinnlos, weil es ja eine
wilde Mischung von Deutsch und Englisch ist.
Um so mehr Spaß macht es, das mit den 100'000 Wörtern zu vergleichen,
die schließlich mal im Goethe-Wörterbuch sein sollen, wenn es fertig
ist. Eine schnelle Webrecherche hat leider nichts zur Frage ergeben,
wie entsprechende Schätzungen für Thomas Mann aussehen. Einmal, wenn
ich gerne Kennzahlen vergleichen würde…
Aus dieser Kurve lässt sich ablesen, dass wir in acht Tagen knapp 3500
SARS-2-Fälle auf Intensivstationen haben werden. Wie, verrate ich in
diesem Artikel.
In meinen Corona-Überlegungen gestern habe ich mich mal wieder
gefragt, wie lange wohl die „Intensiv-Antwort“ dem Inzidenzsignal
nachläuft, wie viele Tage es also dauert, bis sich ein Anstieg in den
Inzidenzen in der Intensivbelegung reflektiert. Diese Frage ist, wie
ich unten ausführe, derzeit ziemlich relevant im Hinblick auf
Überlegungen, wie lange wir eigentlich noch Zeit haben, um massenhafte
Triage in (oder vor) unseren Intensivstationen abzuwenden.
Meine Null-Annahme für diese Verzögerung war seit Mai 2020 – nach einer
entsprechenden Ansage eines befreundeten Anästhesisten – „eher so drei
Wochen“. Bei nährem Nachdenken ist mir gestern aber aufgefallen, dass er
wohl eher „von Infektion bis Intensiv“ gemeint haben wird, und dann ist
die Antwort sicher schneller, denn von Infektion bis Meldung vergeht
normalerweise wohl mindestens eine Woche. Aber: Ich muss nicht
raten. Wir spielen hier mit Kennzahlen, die vielleicht in der Realität
nicht immer viel bedeuten, aber zumindest klar definiert sind. Daher
lässt sich der Verzug auf der Basis von RKI- und DIVI-Zahlen
nachrechnen.
Ich verrate gleich mal das Ergebnis: ich komme für die zweite Welle auf
gut fünf Tage Verzug der Intensiv-Antwort, für die dritte auf etwa
sieben Tage, für die vierte Welle auf acht bis neun Tage. Wie ich unten
ausführe, sind das relativ gute Nachrichten.
Zeitreihen
Wie habe ich das gerechnet? Nun, die Korrelation von Zeitreihen ist ein
ganzer Satz von Wissenschaften, bei denen es meist darum geht, ungleiche
Abdeckungen, unregelmäßig gesetzte Messpunkte sowie allerlei Rauschen und
Schmutz weggefummelt zu kriegen, ohne allzu viele Informationen zu
verlieren oder, vielleicht schlimmer, damit Artefakte einzubauen.
Die so gereinigten Daten lassen sich dann zum Beispiel geeignet skaliert
und verschoben übereinanderlegen. Tatsächlich sind die Parameter dieser
Transformationen im Regelfall (und gewissermaßen auch hier) viel
interessanter als die Zeitreihen selbst[1]. Es gibt daher
zahlreiche mathematische Verfahren, die das von einer Augenmaß-Übung in
etwas verwandeln, das reproduzierbar und auch quantifizierbar ist.
Vorsicht: ich bin da kein Experte und gehe hier nur mit nicht allzu
schwer erkranktem Menschenverstand ran, verwende also (zumindest in
Summe) gerade kein wirklich wohldurchdachtes Verfahren. Wer sowas wie
das hier für Hausaufgaben oder Hausarbeiten verwendet, tut das auf
eigene Gefahr.
Andererseits bin ich recht zuversichtlich, dass der Kram insgesamt schon
stimmt.
Ausgangsdaten sind meine aus RKI-Berichten gescrapten
Intensivbelegungen und ein RKI-Sheet (in, ach weh, „Office Open
XML“ a.k.a. XSLX – muss das sein?) mit den Inzidenzen. Dabei ist
das erste Problem, dass ich aus verschiedenen Gründen nicht für jeden
Tag Belegungszahlen habe, und so ist mein erster Schritt, fehlende
Punkte zu interpolieren. Das Scipy-Paket macht es leicht, aus einem
Satz von Zeit/Wert-Paaren (die Zeit wird in den Lesefunktionen auf
Sekunden seit einer Epoche gewandelt) ein handliches Array zu rechnen:
grid_points = numpy.arange(
raw_crits[0][0],
raw_crits[-1][0],
86400) # ein Tag in Sekunden
critnums = interpolate.griddata(
raw_crits[:,0], raw_crits[:,1], grid_points)
Ich wollte diese Interpolation eigentlich visualisieren, habe aber keine
gute Stelle gefunden, an der sie einen sichtbaren Unterschied
gemacht hätte, und entscheidend ist eigentlich nur, dass ich ab diesem
Schritt blind mit Arrays arbeiten kann; deren Index ist zunächst die
Zahl der Tage seit dem ersten Tag mit Daten, hier speziell dem
11.8.2020, denn damals habe ich mit dem Screenscrapen der DIVI-Daten
angefangen.
Übergeplottete Kurven
Wenn ich diese interpolierten Kurven übereinanderlege, kommt das hier
heraus:
Weil das, wie gesagt, erst im August 2020 anfängt, fehlt die erste
Welle.
Das bloße Auge reicht für die Bestätigung der Erwartung, dass die
Intensivbelegung der Inzidenzkurve meist etwas hinterherläuft, wenn auch
nicht so, dass mensch hoffen könnte, die beiden durch etwas Schieben
global übereinanderzubekommen. Die großen Zacken in den Inzidenzen
durch Weihnachten und Ostern finden sich in der Intensivbelegung
gar nicht wieder, was ein klares Zeichen ist, dass sie weitgehend
Erfassungsartefakte sind. In der Hinsicht wären die „großen“ RKI-Zahlen
mit Referenzdaten (vgl. die Film-Geschichte) bestimmt besser, aber
ich wollte für dieses Ding nicht die 200 Megabyte durchkämmen, zumal die
„kleinen“ RKI-Daten besser auf die Meldedaten aus den Tagesberichten
passen, um die es mir hier ja geht.
Vor allem fällt auf, dass meine Jammerei darüber, dass der
Impffortschritt die Intensivantwort nicht wesentlich abgeflacht hat,
unzutreffend ist: Mit der Skalierung aus dem Plot liegen Inzidenz und
Belegung in der zweiten und dritten Welle ziemlich übereinander, während
in der vierten Welle doch ein knapper Faktor zwei dazwischenliegt; da
scheint die Impfung doch ein wenig gegenüber Delta zu gewinnen (aber,
klar, nirgendwo hinreichend).
Ich hatte erwartet, dass die abfallenden Flanken der Intensivkurven
deutlich flacher sind als die der Inzidenzkurven, weil Leute unter
Umständen lang auf Intensiv liegen und es entsprechend lang dauern
sollte, bis sich die Stationen wieder leeren. Das sieht im Abfall der
zweiten Welle auch ein wenig so aus, nicht jedoch bei dem der dritten
Welle. Bei ihr fällt die Intensivbelegung sehr treu mit der Inzidenz.
So viele LangzeitpatientInnen gibt es glücklicherweise wohl doch nicht.
Nach Glätten differenzierbar
Wie kann ich jetzt den Verzug zu quantifizieren? Mein (wie gesagt eher
intuitiv gefasster) Plan ist, über die Ableitung der jeweiligen Kurven
zu gehen, und zwar aus der Überlegung heraus, dass mich ja Veränderungen
viel mehr als Pegel interessieren. Nun habe ich aber keine
differenzierbaren Funktionen, sondern lediglich Arrays, bei denen ich
Ableitungen allenfalls durch Subtrahieren benachbarter Elemente
simulieren kann. Solche numerischen „Ableitungen“ reagieren ziemlich
empfindlich auf das Gewackel („Rauschen“), das es in realen Daten immer
gibt („Subtraktion ist in der Regel numerisch schlecht konditioniert“).
Deshalb will ich meine rohen Daten glätten, bevor ich die „Ableitung“
ausrechne, sprich: das Rauschen rausnehmen, ohne das Signal wesentlich
zu verzerren.
Glättung heißt eigentlich immer, Kurvenpunkte in einem Zelle für Zelle
über die Daten laufenden Fenster zu mitteln, also z.B., indem mensch je
fünf Nachbarpunkte rechts und links auf den aktuellen Punkt draufaddiert
und ihn dann durch die durch elf geteilte Summe ersetzt. Mit diesem
ganz naiven Rezept bekommen relativ weit entfernte Werte aber genauso
viel Einfluss auf den aktuellen Punkt wie die unmittelbaren Nachbarn.
Das modelliert meist die sachlichen Grundlagen des Rauschens nur
schlecht. Es ist auch aus theoretischeren Gründen normalerweise eher
ungünstig.
Der eher theoretische Hintergrund ist grob, dass bei der Glättung
letztlich zwei Funktionen gefaltet werden. Das ist äquivalent dazu,
die Spektren der beiden Signale (ihre Fouriertransformierten) zu
multiplizieren und dann wieder zurückzutransformieren. Bei einem
einfachen Fenster des oben skizierten Typs („Rechteckfunktion“) gibts
nun sehr scharfe Kanten, die wiederum zu einem sehr breiten Spektrum
führen, so dass auch das Spektrum der geglätteten Funktion allerlei
unwillkommene Features bekommen kann (manchmal ist das aber auch genau
das, was mensch haben will – hier nicht).
Wie auch immer: scipy macht es einfach, mit einer lärmarmen Funktion –
die sieht ein wenig gaußig aus und ist im nächsten Plot im kleinen Inset
zu sehen – zu glätten, nämlich etwa so:
import numpy
from scipy import signal
smoothing_kernel = numpy.kaiser(20, smoothing_width)
smoothing_kernel = smoothing_kernel/sum(smoothing_kernel)
convolved = signal.convolve(arr, smoothing_kernel, mode="same"
)[smoothing_width:-smoothing_width]
Die Division durch die Summe von smoothing_kernel in der zweiten
Zeile sorgt dafür, dass sich an der „Höhe“ der geglätteten Funktion
insgesamt nichts ändert: Sozusagen ausgeklammert ist die Faltung eine
Multiplikation mit eins. Das Wegschneiden der Ränder in der letzten
Zeile wiederum entfernt Punkte, bei denen fehlende Werte am Anfang und
Ende der Zeitreihe im Fenster waren. Scipy ersetzt die durch Nullen, so
dass die geglätteten Werte am Rand steil abfallen. Was ich hier mache,
entspricht technisch dem valid-Mode der convolve-Funktion. Nur weiß ich
hier zuverlässig, wie lang das Array am Schluss ist.
Der Effekt, hier auf Indzidenzdaten der vierten Welle:
Damit kann ich jetzt meine numerische „Ableitung“ bilden, ohne dass mir
das Ergebnis furchtbar rauscht:
diff = convolved[1:]-convolved[:-1]
Die nächsten beiden Grafiken zeigen diese Pseudo-Ableitungen für
Inzidenz und Intensivbelegung. Ich habe jeweils in blau reingemalt, wie
es ohne Glättung aussehen würde, um deutlich zu machen, warum diese eine
gute Idee ist und was ich mit „furchtbar rauschen“ meine.
Weiterverwendet werden natürlich die orangen Verläufe:
In der Inzidenzkurve fallen wieder Weihnachten und Ostern besonders auf,
weil sie selbst in den geglätteten Graphen noch wilde Ausschläge
verursachen.
In der Zeit verschieben
Schon der optische Eindruck aus dem Rohdaten-Plot legt nahe, die
einzelnen Wellen getrennt zu untersuchen, und das ist angesichts von
über die Zeit stark veränderlichen Viren, Testverhältnissen,
demographischen Gegebenheiten und nichtpharamzeutischen Maßnahmen sicher
auch sachlich geboten.
Deshalb hier zunächst der Verlauf der Ableitungen von Inzidenzen und
Intensivbelegung in der aktuellen vierten Welle (das ist eine
Kombination der rechten Enden der orangen Graphen der letzten beiden
Plots):
In dem Graphen steckt noch eine weitere Normalisierung. Und zwar habe
ich für beide Arrays etwas wie:
incs /= sum(abs(incs))
laufen lassen. Damit ist die Fläche zwischen den Kurven …
Über einen Artikel in der Wochenzeitung Kontext bin ich auf eine
Kleinstudie des Zentrums für europäische Wirtschaftsforschung (ZEW)
gestoßen, auf die ich vor allem im Hinblick auf eine spätere Nutzung zur
Mythenstörung kurz eingehen möchte.
Zu bedenken ist zunächst, dass das ZEW gewiss in keinem Verdacht steht,
irgendwelche fortschrittlichen Ideen zu hegen. So gehört zu deren
aktuellen „Empfehlungen für die Wirtschaftspolitik“ offensichtlicher
Quatsch der Art „Standardisierte Altersvorsorgeprodukte einführen“ oder
Deflektorschilde gegen eine entspanntere, arbeitsärmere und
umweltfreunlichere Gesellschaft des Typs „Kostengerechte Aufteilung der
CO2-Reduktionen zwischen den Sektoren“; aktuelle Pressemitteilungen
beten marktradikale Wirrnisse herunter wie „Lokale Preisanreize im Strommarkt
setzen“ (Faustregel: „Anreiz“ heißt im Klartext: Geld von unten nach
oben umverteilen) oder „Bundesnetzagentur sollte weiterhin auf Auktionen
setzen“, ganz als sei 1998.
Ausgerechnet diese Leute haben in ihrer Kleinstudie zu den
fiskalischen und ökonomischen Folgen der aktuellen Parteiprogramme
herausgefunden, dass das Programm der Linken den Staathaushalt um 37
Milliarden Euro entlasten würde, während die FDP den Haushalt mit 88
Millarden Euro belasten würde und die CDU immer noch 33 Millarden Euro
mehr Staatsdefizit ansagt.
So viel zur Frage fiskalischer Verantwortung in der Theorie, soweit
also mensch Wahlprogramme ernstnehmen will. Zumindest sollte die Studie
traugen, um die Erzählungen von „wirtschaftlicher Vernunft“ bei den
Rechtspartien als Legenden zu entlarven.
Die Studie liefert weiter Hinweise zum Thema „Turkeys voting for
Christmas“, also Armen, die Rechtsparteien wählen (davon gibt es
augenscheinlich einen ganzen Haufen): Das VEW hat nämlich auch die
Folgen der Programme für den Gini-Koeffizienten abgeschätzt, also
einer Metrik für die Ungleichheit der Einkommen in einer Gesellschaft, der
mit wachsender Ungleichheit wächst. Souveränder Spitzenreiter dabei ist
die AfD, die die Ungleichheit in dieser Metrik um 3.8% verschärfen
würde, wo selbst die FDP die Dinge nur 3.4% schlimmer machen will (und
die CDU um 1.6%). Demgegenüber würde das Wahlprogramm der Linken – take
this, ExtremismustheoretikerInnen! – die Ungleichheit um knapp 15%
reduzieren. Wenn denn irgendwas davon umgesetzt würde, käme sie an die
Regierung; spätestens nach der Katastrophe der Schröder-Administration
dürfte klar sein, dass das ungefähr so wahrscheinlich ist wie ein
ernsthaftes Aufbegehren gegen den permanenten Bürgerrechtsabbau durch
eine FDP in der Regierung. Die Grünen würden laut VEW die Ungleichheit
um 6.5% reduzieren, und selbst die vom für Cum Ex und Hartz IV bekannten
Scholz geführte SPD wäre noch mit -4.3% dabei.
Klar: das Ganze ist eine stark zirkuläre Argumentation, denn Programme
der Parteien haben viel mit den Methoden des ZEW und Metriken wie dem
Gini-Koeffizienten gemein, alle drei aber sicher nicht viel mit
irgendwelchen Realitäten. In der gemeinsamen, wenn auch hermetischen
Logik bleibt festzuhalten: die bekennenden Rechtspartien betreiben
unzweifelhaft die Umverteilung von unten nach oben auf Kosten des
Staatshaushalts.
Und das taugt ja vielleicht später nochmal für ein Argument innerhalb
dieser hermetischen Welt.
Ich bin ja bekennender Leser von Fefes Blog, und ich gebe offen zu, dass
ich dort schon das eine oder andere gelernt habe. Zu den für mich
aufschlussreichsten Posts gehört dieser aus dem September 2015, der
mir seitdem nicht mehr aus dem Sinn gegangen ist, und zwar wegen der
Unterscheidung zwischen Kulturen der Ehre (die mensch sich verdienen und
die mensch dann verteidigen muss) und denen der Würde (die mensch
einfach hat).
Der Rest des Posts ist vielleicht nicht der scharfsinnigste Beitrag zur
Identitätsdebatte, und klar gilt auch Robert Gernhardts „Die Würde des
Menschen ist ein Konjunktiv“ weiter, aber der zentrale Punkt ist:
Artikel 1 Grundgesetz ist eine Befreiung von dem ganzen Unsinn von Ehre
und insofern ein großer Schritt in die Moderne. Das ist mir so erst
damals im September 2015 klar geworden.
Und seitdem habe ich mich um so mehr gewundert über den Stellenwert, den
„Gesicht nicht verlieren“ in „der Politik“ (und das schließt schon
Bezirksvorsitzende von Gewerkschaften ein) immer noch hat. Wo außerhalb
der Krawattenliga gibt es sonst noch „Ehrenerklärungen“ wie neulich
bei der CDU (von vor 20 Jahren ganz zu schweigen) oder kräuseln sich
nicht die Zehennägel, wenn jemand wie Westerwelle weiland verkündete:
„Ihr kauft mir den Schneid nicht ab“?
Um so mehr war ich angetan, als zumindest Angela Merkel diese Logik des
18. Jahrhunderts gestern durchbrochen hat und einfach mal „ich hab
Scheiße gebaut“ gesagt hat. Und es tröstet etwas, dass zumindest die
heutige Presseschau in weiten Teilen nicht das unsägliche Genöle von
Vertrauensfragen aus dem Bundestag gestern reflektiert.
Andererseits: Keine Presseschau ohne fassungsloses Kopfschütteln, wenn
nämlich die Süddeutsche schreibt:
Hätte die Bundesregierung stattdessen selber genug Impfdosen
geordert, und zwar nicht zuletzt bei Biontech im eigenen Land, dem
Erfinder des ersten Corona-Vakzins, befände sich Deutschland jetzt
nicht am Rande der Hysterie.
Hätte die Süddeutsche gesagt: „dafür gesorgt, dass so oder so alles, was
an Abfüllkapazität da ist, anfängt, Impfstoff abzufüllen, sobald
absehbar ist, dass es mit der Zulassung was wird“ – ok, das wäre ein
Punkt. Das augenscheinlich auch im Ernstfall herrschende Vertrauen in
„den Markt“ ist natürlich böser Quatsch. Aber auch überhaupt
nichts Neues. Und die Süddeutsche sitzt in dem Punkt in einem Glashaus
mit ganz dünnen Scheiben.
Aber sie redet auch vom „ordern“, was im Klartext heißt: „wir wollen
schneller geimpft sein als die anderen“ – das ist, noch klarerer Text,
anderen Leuten den Impfstoff wegnehmen. Meinen die Süddeutschen das
ernst?
Ich bin ja ohnehin in den letzten Wochen in der unangenehmen Situation,
meine Regierung zu verteidigen. Das habe ich, glaube ich, noch nie
gemacht. Aber im schwierigen Lavieren zwischen autoritärem Durchgriff –
etwa, alle Leute bei sich zu Hause einsperren – und einem
Laissez-Faire, das vermutlich fast eine halbe Million Menschen in der
BRD umgebracht hätte, sieht es fast so aus, als hätte der
Gesamtstaat (zu dem ja auch Landesregierungen und vor allem Gerichte
gehören) so ziemlich den Punkt erwischt hat, den „die
Gesellschaft“ sonst auch akzeptiert.
Warum ich das meine? Nun, so sehr ich gegen Metriken als Bestimmer
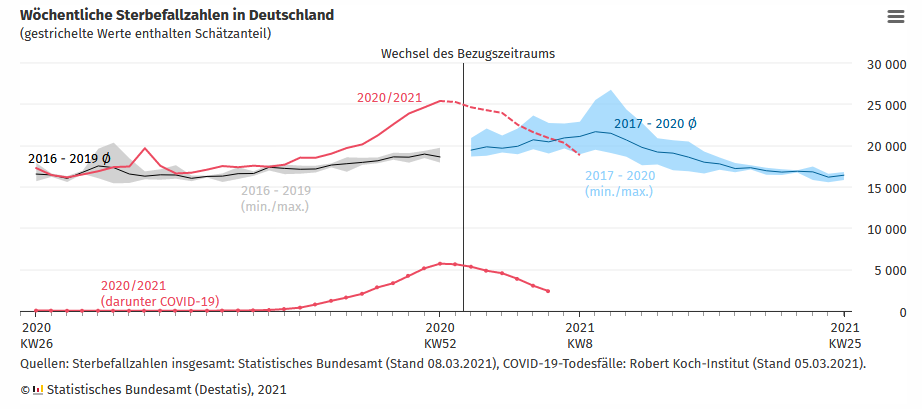
politischen Handelns bin, gibt die Mortalitätskurve doch eine Idee
davon, welche Kompromisse wir eingehen. Das RKI veröffentlicht jeden
Freitag so eine, und die im Bericht vom letzten Freitag sieht so aus:
In Worten: Die Gesamtsterblichkeit war im Corona-Jahr nicht viel anders
als sonst auch, nur kam der Grippe-Peak halt schon im November und
Dezember statt erst im Januar und Februar. Und da wir ja wegen der
Grippe in „normalen“ Jahren auch nicht alle das Winterende in Isolation
verbringen, war das Level an Isolation und Shutdown, das wir am Ende
hatten und das SARS-2 zur Vergleichbarkeit gezähmt hat, offenbar im
Sinne „der Gesellschaft“ gewählt.
Klar: Das hat so wohl niemand geplant. Dass es aber so rausgekommen
ist, dürfte nicht einfach nur Zufall sein. „Schwarmintelligenz“
wird den Grund sicher nicht treffen. Aber irgendwas, das nicht
furchtbar weit davon weg ist, dürfte die Ähnlichkeit der Kurven wohl
schon erklären. Vielleicht: Das, was bei uns von Gewaltenteilung noch
übrig ist?
Ansonsten bereite ich mich schon mal aufs Verspeisen meines Hutes vor,
wenn die „dritte Welle“ jetzt doch noch für einen schlimmen
Mortalitätspeak sorgt.
Die gerade durch die Medien gehende Geschichte von Georg Nüßlein
zeichnet, ganz egal, was an Steuerhinterziehung und
Bestechung nachher übrig bleibt,
jedenfalls das Bild von einem Menschen, der, während rundrum
die Kacke am Dampfen ist, erstmal überlegt, wie er da noch den einen
oder anderen Euro aus öffentlichen Kassen in seine Taschen wandern
lassen kann.
Die Unverfrorenheit mag verwundern, nicht aber, dass Schurken in
die Fraktionsleitung der CSU aufsteigen. Im Gegenteil – seit ich
gelegentlich mal mit wichtigen Leuten umgehe, fasziniert mich die
Systematik, mit der die mittlere Schurkigkeit von Menschen mit ihrer
Stellung in der Hierarchie steil zunimmt: Wo in meiner unmittelbaren
Arbeitsumgebung eigentlich die meisten Leute recht nett sind, gibt es
unter den Profen schon deutlich weniger Leute mit erkennbarem Herz. Im
Rektorat wird es schon richtig eng, und im Wissenschaftsministerium
verhalten sich oberhalb der Sekretariate eigentlich alle wie Schurken,
egal ob nun früher unter Frankenberg oder jetzt unter Bauer.
Tatsächlich ist das mehr oder minder zwangsläufig so in Systemen, die
nach Wettbewerb befördern. Alles, was es für ein qualitatives
Verständnis dieses Umstands braucht, sind zwei Annahmen, die vielleicht
etwas holzschnittartig, aber, so würde ich behaupten, schwer zu
bestreiten sind.
Es gibt Schurken und Engel
Wenn Schurken gegen Engel kämpfen (na ja, wettbewerben halt), haben
die Schurken in der Regel bessere Chancen.
Die zweite Annahme mag nach dem Konsum hinreichend vieler
Hollywood-Filme kontrafaktisch wirken, aber eine gewisse moralische
Flexibilität und die Bereitschaft, die Feinde (na ja, Wettbewerber halt)
zu tunken und ihnen auch mal ein Bein zu stellen, dürfte unbestreitbar
beim Gewinnen helfen.
Um mal ein Gefühl dafür zu kriegen, was das bedeutet: nehmen wir an, der
Vorteil für die Schurken würde sich so auswirken, dass pro
Hierarchieebene der Schurkenanteil um 20% steigt, und wir fangen mit 90%
Engeln an (das kommt für mein soziales Umfeld schon so in etwa hin, wenn
mensch hinreichend großzügig mit dem Engelbegriff umgeht). Als Nerd
fange ich beim Zählen mit Null an, das ist also die Ebene 0.
Auf Ebene 1 sind damit noch 0.9⋅0.8, also
72% der Leute Engel, auf Ebene 2
0.9⋅0.8⋅0.8, als knapp 58% und so fort, in Summe also 0.9⋅0.8n
auf Ebene n. Mit diesen Zahlen sind in Hierarchieebene 20 nur noch 1%
der Leute Engel, und dieser Befund ist qualitativ robust gegenüber
glaubhaften Änderungen in den Anfangszahlen der Engel oder der Vorteile
für Schurken.
Tatsächlich ist das Modell schon mathematisch grob vereinfacht, etwa
weil die Chancen für Engel sinken, je mehr Schurken es gibt, ihr Anteil
also schneller sinken sollte als hier abgeschätzt. Umgekehrt sind natürlich
auch Leute wie Herr Nüßlein nicht immer nur Schurken, sondern haben
manchmal (wettbewerbstechnisch) schwache Stunden und verhalten sich wie
Engel. Auch Engel ergeben sich dann und wann dem Sachzwang und sind von
außen von Schurken nicht zu unterscheiden. Schließlich ist wohl
einzuräumen, dass wir alle eher so eine Mischung von Engeln und Schurken
sind – wobei das Mischungsverhältnis individuell ganz offensichtlich
stark schwankt.
Eine Simulation
All das in geschlossene mathematische Ausdrücke zu gießen, ist ein
größeres Projekt. Als Computersimulation jedoch sind es nur ein paar
Zeilen, und die würde ich hier gerne zur allgemeinen Unterhaltung und
Kritik veröffentlichen (und ja, auch die sind unter CC-0).
Ein Ergebnis vorneweg: in einem aus meiner Sicht recht
plausiblen Modell verhält sich die Schurkigkeit (auf der Ordinate; 1
bedeutet, dass alle Leute sich immer wie Schurken verhalten) über der
Hierarchiebene (auf der Abszisse, höhere Ebenen rechts) wie folgt (da
sind jeweils mehrere Punkte pro Ebene, weil ich das öfter habe laufen
lassen):
Ergebnis eines Laufs mit einem Schurken-Vorteil von 0.66, mittlere
Schurkigkeit über der Hierarchieebene: Im mittleren Management ist
demnach zur 75% mit schurkigem Verhalten zu rechnen. Nochmal ein paar
Stufen drüber kanns auch mal besser sein. Die große Streuung auf den
hohen Hierarchieebenen kommt aus den kleinen Zahlen, die es
da noch gibt; in meinen Testläufen fange ich mit 220 (also
ungefähr einer Million) Personen an und lasse die 16 Mal Karriere
machen; mithin bleiben am Schluss 16 Oberchefs übrig, und da macht
ein_e einzige_r Meistens-Engel schon ziemlich was aus.
Das Programm, das das macht, habe ich Schurken und Engel getauft,
sunde.py – und lade zu Experimenten damit ein.
Es wird also festgelegt, dass, wenn ein Schurke gegen einen Engel
wettbewerbt, der Schurke mit zu 66% gewinnt (und ich sage mal voraus,
dass der konkrete Wert hier qualitativ nicht viel ändern wird), während
es ansonsten 50/50 ausgeht. Das ist letztlich das, was in _WIN_PROB
steht.
Und dann gibt es das Menschenmodell: Die Person wird, wir befinden uns
in gefährlicher Nähe zu Wirtschafts„wissenschaften“, durch einen
Parameter bestimmt, nämlich die Engeligkeit (angelicity; das Wort gibts
wirklich, meint aber eigentlich nicht wie hier irgendwas wie
Unbestechlichkeit). Diese ist die Wahrscheinlichkeit, sich anständig zu
verhalten, so, wie das in der is_rogue-Methode gemacht ist: Wenn
eine Zufallszahl zwischen 0 und 1 (das Ergebnis von random.random())
großer als die Engeligkeit ist, ist die Person gerade schurkig.
Das wird dann in der wins_against-Methode verwendet: sie bekommt
eine weitere Actor-Instanz, fragt diese, ob sie gerade ein Schurke ist,
fragt sich das auch selbst, und schaut dann in _WIN_PROB nach, was
das für die Gewinnwahrscheinlichkeit bedeutet. Wieder wird das gegen
random.random() verglichen, und das Ergebnis ist, ob self gegen
other gewonnen hat.
Der nächste Schritt ist die Kohorte; die Vorstellung ist mal so ganz in
etwa, dass wir einem
Abschlussjahrgang bei der Karriere folgen. Für jede Ebene gibt es eine
Aufstiegsprüfung, und wer die verliert, fliegt aus dem Spiel. Ja, das
ist harscher als die Realität, aber nicht arg viel. Mensch fängt mit
vielen Leuten an, und je weiter es in Chef- oder Ministerialetage geht,
desto dünner wird die Luft – oder eher, desto kleiner die actor-Menge:
class Cohort:
draw = random.random
def __init__(self, init_size):
self.actors = set(Actor(self.draw())
for _ in range(init_size))
def run_competition(self):
new_actors = set()
for a1, a2 in self.iter_pairs():
if a1.wins_against(a2):
new_actors.add(a1)
else:
new_actors.add(a2)
self.actors = new_actors
def get_meanness(self):
return 1-sum(a.angelicity
for a in self.actors)/len(self.actors)
(ich habe eine technische Methode rausgenommen; für den vollen Code vgl.
oben).
Interessant hier ist vor allem das draw-Attribut: Das zieht nämlich
Engeligkeiten. In dieser Basisfassung kommen die einfach aus einer
Gleichverteilung zwischen 0 und 1, wozu unten noch mehr zu sagen sein
wird. run_competition ist der Karriereschritt wie eben beschrieben,
und get_meanness gibt die mittlere Schurkigkeit als eins minus der
gemittelten Engeligkeit zurück. Diesem Wortspiel konnte ich nicht
widerstehen.
Es gäbe zusätzlich zu meanness noch interessante weitere Metriken, um
auszudrücken, wie schlimm das Schurkenproblem jeweils ist,
zum Beispiel: Wie groß ist der Anteil der Leute mit Engeligkeit unter
0.5 in der aktuellen Kohorte? Welcher Anteil von Friedrichs
(Engeligkeit<0.1) ist übrig, welcher Anteil von Christas
(Engeligkeit>0.9)? Aus wie vielen der 10% schurkgisten Personen „wird
was“? Aus wie vielen der 10% Engeligsten? Der_die Leser_in ahnt schon,
ich wünschte, ich würde noch Programmierkurse für Anfänger_innen geben:
das wären lauter nette kleine Hausaufgaben. Andererseits sollte mensch
wahrscheinlich gerade in so einem pädagogischen Kontext nicht
suggerieren, dieser ganze Metrik-Quatsch sei unbestritten. Hm.
Nun: Wer sunde.py laufen lässt, bekommt Paare von Zahlen
ausgegeben, die jeweils Hierarchiestufe und meanness der Kohorte angeben.
Die kann mensch dann in einer Datei sammeln, etwa so:
und so fort. Und das Ganze lässt sich ganz oldschool mit gnuplot
darstellen (das hat die Abbildung oben gemacht), z.B. durch:
plot "results.txt" with dots notitle
auf der gnuplot-Kommandozeile.
Wenn mir wer ein ipython-Notebook schickt, das etwa durch matplotlib
plottet, veröffentliche ich das gerne an dieser Stelle – aber ich
persönlich finde shell und vi einfach eine viel angenehmere Umgebung...
Anfangsverteilungen
Eine spannende Spielmöglichkeit ist, die Gesellschaft
anders zu modellieren, etwa durch eine Gaußverteilung der Engeligkeit,
bei der die meisten Leute so zu 50% halb Engel und halb Schurken sind
(notabene deckt sich das nicht mit meiner persönlichen Erfahrung, aber
probieren kann mensch es ja mal).
Dazu ersetze ich die draw-Zuweisung in Cohort durch:
Die „zwei Sigma“, also – eine der wichtigeren Faustformeln, die
mensch im Kopf haben sollte – 95% der Fälle, liegen hier zwischen 0 und
1. Was drüber und drunter rausguckt, wird auf „immer Engel“ oder „immer
Schurke“ abgeschnitten. Es gibt in diesem Modell also immerhin 2.5%
Vollzeitschurken. Überraschenderweise sammeln sich die in den ersten 16
Wettbewerben nicht sehr drastisch in den hohen Chargen, eher im
Gegenteil:
Deutlich plausibler als die Normalverteilung finde ich in diesem Fall ja
eine …
Noch vor einem Jahr hatte sich kaum jemand vorstellen können, wie
schnell die Staaten die Grenzen im März 2020 geschlossen haben – aber,
das lässt sich hier leider wirklich nicht wegdiskutieren, im Prinzip
können Bewegungseinschränkungen bei so einer Pandemie je nach
Verteilung und Entwicklung schon mal nicht einfach nur atavistische
Reflexe sein, und so will ich einmal nicht allzu sehr die Zähne
fletschen.
Die Ergebnisse in der zentralen Frage – letztlich: Wärs besser gewesen,
wir wären alle daheim geblieten? – sind wenig überraschend, wie auch das
Fazit zur Frage der Massentests für Heimkehrer_innen:
Ein längeres Angebot zur freiwilligen, kostenlosen Testung für
Reiserückkehrer hätte vielleicht die Eintragungen vor und während der
Herbstferien besser erfasst, die zweite Infektionswelle aber nicht
verhindert.
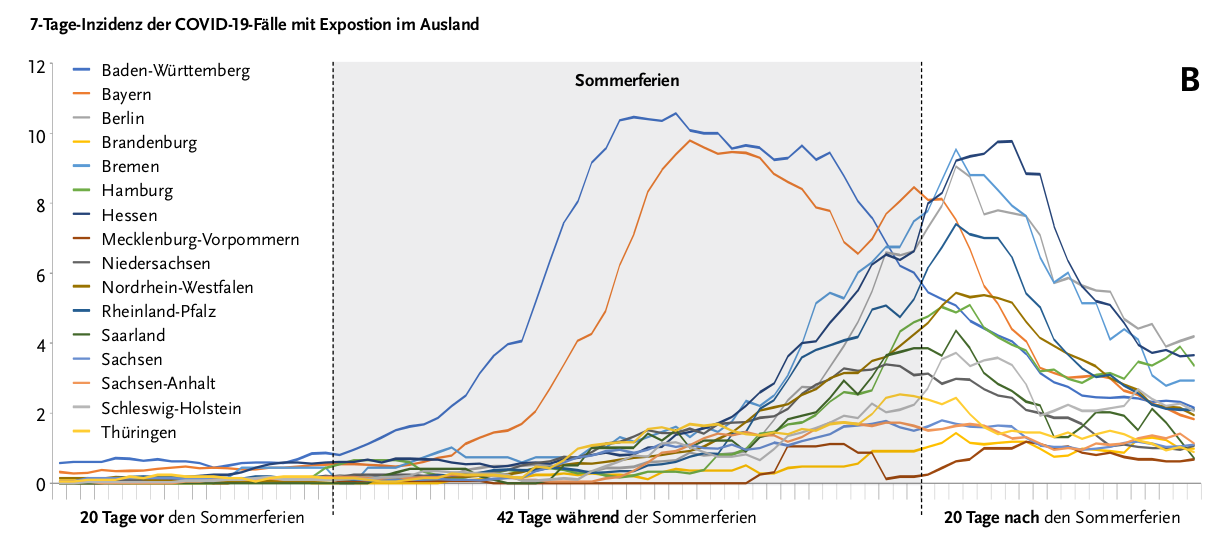
Richtig bemerkenswert fand ich hingegen folgende Abbildung in dem
Artikel:
Sie entstand, indem die RKI-Leute erstmal als Zeiteinheit „Tage vor oder
nach dem Beginn der Sommerferien im jeweiligen Bundesland“ gewählt
haben. An der Ordinate stehen die üblichen Wocheninzidenzen pro 100000
Einwohner_innen, und zwar für Fälle, für die eine Exposition im
Ausland bekannt ist. Insofern ist es kein Wunder, dass die Zahlen im
Laufe der Zeit hochgehen. Das muss schon allein aufgrund der
gestiegenen Reisetätigkeit so sein.
Wertvoll wird die Abbildung aber als Mahnung, bei allen Metriken immer
zu bedenken, was wie gemessen wurde. Denn richtig auffallend verhalten
sich hier Bayern und Baden-Württemberg scheinbar anders als alle
anderen: Ihre Kurven steigen erhebnlich früher und steiler als die der
anderen Bundesländer.
Es wäre jedoch unvernünftig, anzunehmen, die Dinge hätten sich in den
anderen Bundesländern in der Realität wesentlich anders verhalten
(jedenfalls, soweit es die westlichen Bundesländer betrifft). Und in
der Tat liefert schon das RKI die Erklärung für den Unterschied: Die
Südländer hatten einfach so spät Ferien, dass ihre Reiserückkehrenden in
die allgemeine Testpflicht fielen sind und mithin die Erfassung
Infizierter früher in deren Krankheitsverlauf und darüber hinaus bereits
bei den Indexfällen passierte.
Ob das jetzt eine weise Verwendung von Ressourcen war oder nicht, muss
ich glücklicherweise nicht entscheiden. Zumindest für die nächsten
Jahre aber – solange sich die Menschen noch an die Diskussion um die
Massentests im Sommer 2020 erinnern – ist diese Grafik aber, glaube ich,
eine wunderbare Art, den Einfluss von Messung (und in diesem Fall von
Politik) auf scheinbar unumstößliche Grafiken und Metriken zu
illustrieren.
Ich werde das beim nächsten Mensen-Ranking auspacken. Oder, wenn wieder
mal das Bruttoinlandsprodukt verkündet wird.
![[RSS]](../theme/image/rss.png)